
Jpa Web Application 5
Api
Thymeleaf와 같은 View Template을 활용하여 직접 View page을 개발을 해도 되지만, 실제 어플리케이션 개발에 있어서는 Api 형태로 기능을 제공하여, Front에서 Api를 호출하여 필요한 데이터를 주고 받는 방식의 개발을 진행한다.
Member Api
회원 등록
회원 등록 v1
@RestController
@RequiredArgsConstructor
public class MemberApiController {
private final MemberService memberService;
@PostMapping("/api/v1/members")
public CreateMemberResponse saveMemberV1(@RequestBody @Valid Member member) {
Long id = memberService.join(member);
return new CreateMemberResponse(id);
}
@Data
static class CreateMemberResponse{
private Long id;
public CreateMemberResponse(Long id) {
this.id = id;
}
}
}
위의 PostMapping을 통해 회원 등록 요청에 대한 처리를 진행한다. 하지만 위와 같이 엔티티를 직접 주고 받는 방식으로 Api를 설계하게 되면, 엔티티와 Api 설계간에 의존관계가 형성되어, 엔티티의 수정이 화면의 수정으로 이어지는 문제가 발생한다. 또한 엔티티의 모든 정보가 노출되기 때문에 비밀번호와 같은 민감한 정보가 노출되는 문제가 발생한다. 따라서, Api 와 같은 외부에 공개되는 정보에 대해서는 3rd party class을 생성해서 해당 클래스를 주고 받는 식으로 의존관계를 방지한다.
별도의 Dto 사용을 통해 얻을 수 있는 효과는 아래와 같다
- 민감한 정보의 노출 방지(예: 비밀번호)
- 엔티티의 수정이 화면의 수정으로 이어지지 않는다.즉, 엔티티와 화면 간에 의존관계가 없다
- 각 화면별로 사용되는 정보가 다르기 때문에 이에 맞는 Dto 구성을 통해 각각의 화면에 따라 다른 로직을 적용하는 것이 가능하다.(예: 검증 로직의 다양화)
회원 등록 v2
@RestController
@RequiredArgsConstructor
public class MemberApiController {
private final MemberService memberService;
@PostMapping("/api/v2/members")
public CreateMemberResponse saveMemberV2(@RequestBody @Valid CreateMemberRequest request) {
Member member = new Member();
member.setName(request.getName());
Long id = memberService.join(member);
return new CreateMemberResponse(id);
}
@Data
static class CreateMemberRequest{
@NotEmpty
private String name;
}
@Data
static class CreateMemberResponse{
private Long id;
public CreateMemberResponse(Long id) {
this.id = id;
}
}
}
Result
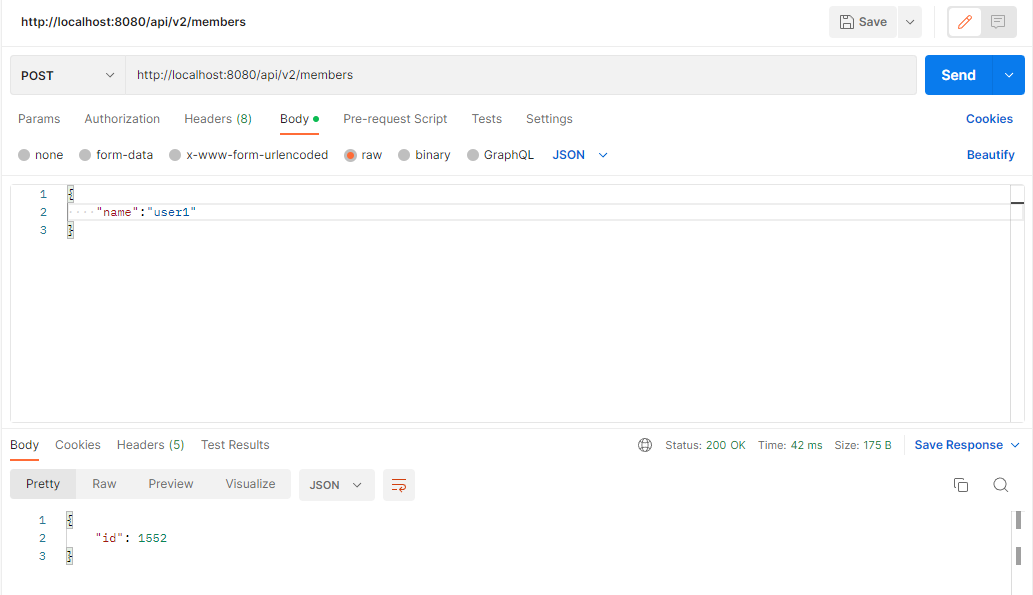
회원 수정
@RestController
@RequiredArgsConstructor
public class MemberApiController {
private final MemberService memberService;
@PostMapping("/api/v2/members/{id}")
public UpdateMemberResponse saveMemberV2(@PathVariable Long id, @RequestBody @Valid UpdateMemberRequest request) {
memberService.update(id, request.getName());
Member findMember = memberService.findOne(id);
return new UpdateMemberResponse(findMember.getId(), findMember.getName());
}
@Data
static class UpdateMemberRequest{
@NotEmpty
private String name;
}
@Data
static class UpdateMemberResponse{
private Long id;
private String name;
public UpdateMemberResponse(Long id, String name) {
this.id = id;
this.name = name;
}
}
}
회원 수정 Api 또한 비슷한 방식으로 등록과 비슷한 방식으로 진행한다.
PutMapping vs PostMapping
두 메소드 모두 데이터를 생성할 때 사용이 가능한 Http Method이다. 단, Put은 멱등성을 가진다는 부분에서 차이점이 있다. 멱등성이란, 여러 번의 호출에도 같은 결과값을 반환하는 것을 의미한다. Put의 경우 리소스를 통째로 대체하기 때문에 여러 번 수행되더라도 서버의 상태가 변경되지 않는다. 하지만, Post는 매번 새로운 데이터의 요청을 처리하기 때문에 post 실행에 따른 서버의 상태가 변경될 수 있다.
Result
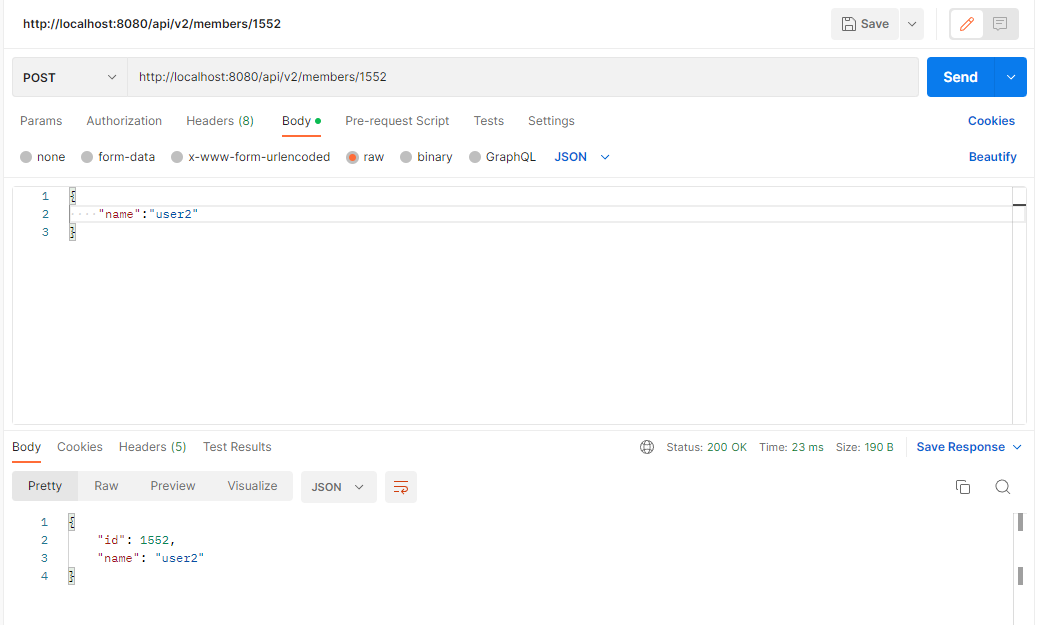
회원 조회
회원 조회를 진행할 때에도 위와 유사한 방식으로 진행하면 된다.
회원 조회 v1
@RestController
@RequiredArgsConstructor
public class MemberApiController {
private final MemberService memberService;
@GetMapping("/api/v1/members")
public List<Member> membersV1(){
return memberService.findMembers();
}
}
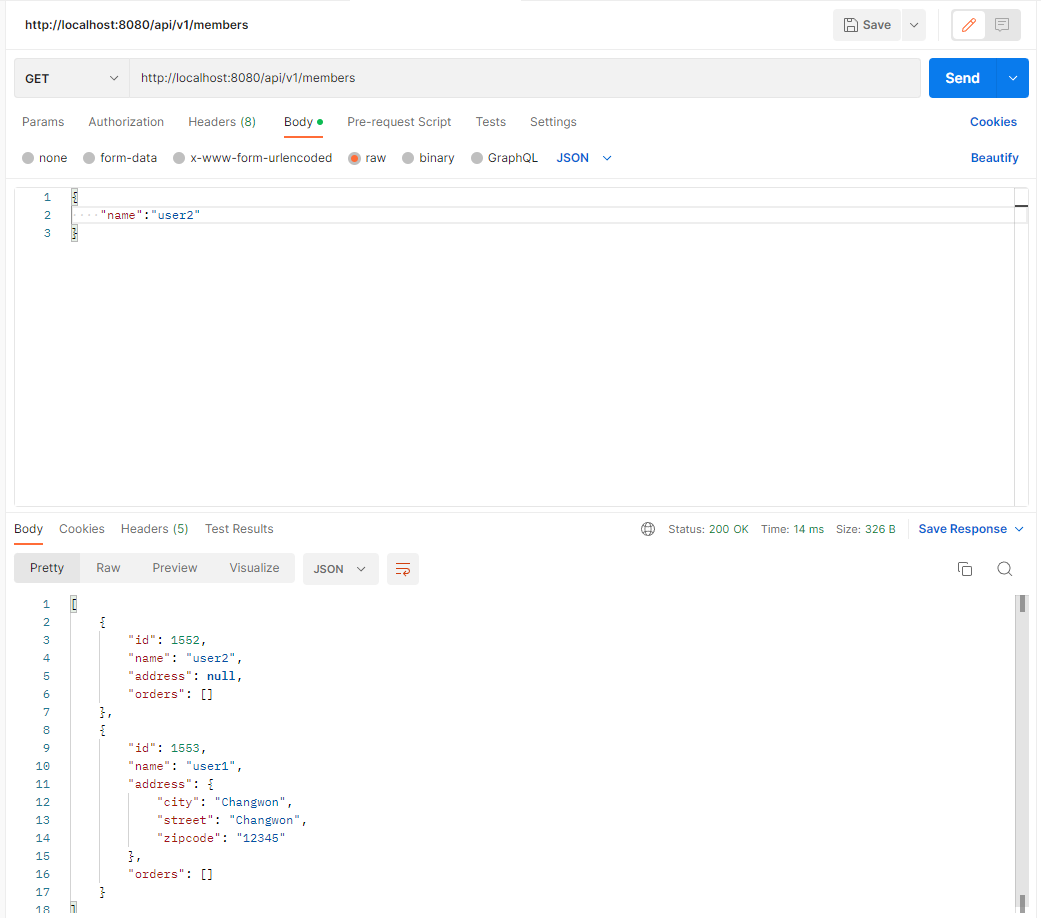
별도의 Dto 없이 바로 엔티티를 반환하게 되면 엔티티의 모든 정보가 노출되는 문제가 발생한다. 화면 별로 필요한 정보가 다르기 때문에 화면에 유동적으로 정보를 반환하기 어렵다. 또한, 컬렉션 형태로 바로 반환하게 되면 Api를 변경하기 어려운 문제가 있다. 컬렉션 형태로 반환되기 때문에 컬렉션의 사이즈 정보와 같은 부가정보를 같이 포함할 수 없다. 그렇기 때문에 컬렉션 타입으로 바로 반환하지 않고 Result class와 같이 하나의 새로운 결과 클래스를 생성해서 한번 감싸서 결과를 반환한다.
회원 조회 v2
@RestController
@RequiredArgsConstructor
public class MemberApiController {
private final MemberService memberService;
@GetMapping("/api/v2/members")
public Result membersV2() {
List<Member> members = memberService.findMembers();
List<MemberDto> collect = members.stream()
.map(m -> new MemberDto(m.getName()))
.collect(Collectors.toList());
return new Result(collect.size(),collect);
}
@Data
@AllArgsConstructor
static class Result<T>{
private int count;
private T data;
}
@Data
@AllArgsConstructor
static class MemberDto{
private String name;
}
}
위와 같이 Result<T> 클래스를 생성해서 데이터를 반환하고 필요하면 count와 같이 변수를 추가해서 결과를 반환하는 것이 가능하다.
Result
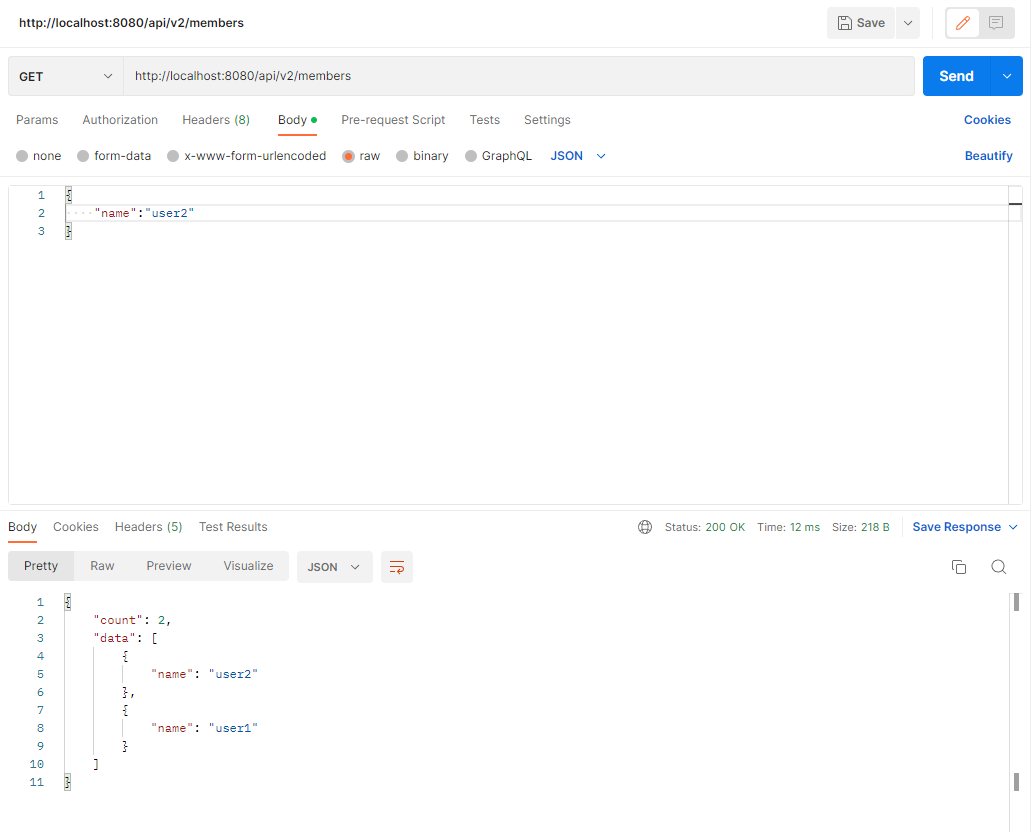
Order
주문 조회
주문 엔티티의 경우, 아래와 같이 연관관계를 가지는 필드가 많기 때문에 회원 조회보다 까다로운 부분이 존재한다.
Order class
@Entity
@Table(name = "ORDERS")
@Data
public class Order {
@Id
@GeneratedValue
@Column(name = "order_id")
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name="member_id")
private Member member;
@OneToMany(mappedBy = "order", cascade = CascadeType.ALL)
private List<OrderItem> orderItems=new ArrayList<>();
@ManyToOne(fetch = FetchType.LAZY, cascade = CascadeType.ALL)
@JoinColumn(name="delivery_id")
private Delivery delivery;
private LocalDateTime orderDate;
@Enumerated(EnumType.STRING)
private OrderStatus status;
...
}
주문 조회 v1 (엔티티를 바로 반환)
@GetMapping("/api/v1/simple-orders")
public List<Order> ordersV1() {
List<Order> orders= orderRepository.findAll(new OrderSearch());
return orders;
}
위와 같이 바로 엔티티를 반환하게 되면 여러 에러가 발생하게 된다.
- order -> member, member -> order 와 같이 양방향 관계로 인한 무한 로딩
양방향 관계가 존재하기 때문에 연관 필드에 대한 쿼리를 수행하게 되면 순환 참조가 발생하여 무한 로딩이 발생한다. 그래서 아래와 같이 한쪽 끝에서는 @JsonIgnore를 추가시켜줘야한다.
@Entity
@Data
public class Member {
@Id
@GeneratedValue
@Column(name="member_id")
private Long id;
private String name;
@Embedded
private Address address;
@JsonIgnore
@OneToMany(mappedBy = "member", cascade = CascadeType.ALL)
private List<Order> orders = new ArrayList<>();
}
- jackson 라이브러리의 프록시 출력 에러
객체 형태로 반환하게 되면 jackson library를 통해 json 형태로 변환된다. 지연 로딩으로 설정해놓은 필드의 경우 프록시 객체가 할당되는데, jaskson library가 프록시 객체에 대한 처리를 할 수 없기 때문에 아래와 같이 하이버네이트 모듈을 등록해서 프록시 처리를 수행한다.
//프록시 객체 json 출력 관련 라이브러리
implementation 'com.fasterxml.jackson.datatype:jackson-datatype-hibernate5-jakarta'
- 프록시 객체 초기화 문제
프록시 객체의 경우 id값만 존재하고, 나머지 필드에 대해서는 값이 없는 상태인데, 그럴 경우 초기화되지 않은 부분에 대해서는 json에 값이 출력되지 않는다. 그렇기 때문에 아래와 같이 프록시를 초기화하는 작업을 수행한다.
@GetMapping("/api/v1/simple-orders")
public List<Order> ordersV1() {
List<Order> orders= orderRepository.findAll(new OrderSearch());
for (Order order : orders) {
order.getMember().getName();
order.getDelivery().getAddress();
}
return orders;
}
엔티티를 직접 반환하게 되면 위와 같은 문제들이 발생하게 되며, 이를 해결하기 위해 코드 수정이 요구되며, 무엇보다도 화면과 비즈니스 로직간에 연관관계가 발생하기 때문에 절대로 엔티리를 직접적으로 반환해서는 안된다.
주문 조회 v2 (Dto 반환)
@GetMapping("/api/v2/simple-orders")
public List<SimpleOrderDto> ordersV2() {
List<Order> orders= orderRepository.findAll(new OrderSearch());
List<SimpleOrderDto> result=orders.stream()
.map(SimpleOrderDto::new)
.collect(Collectors.toList());
return result;
}
@Data
static class SimpleOrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public SimpleOrderDto(Order order) {
this.orderId = order.getId();
this.name = order.getMember().getName(); //getName() 메소드 호출을 통해 프록시 초기화 수행
this.orderDate = order.getOrderDate();
this.orderStatus = order.getStatus();
this.address = order.getDelivery().getAddress();
//getAddress() 메소드 호출을 통해 프록시 초기화 수행
}
}
엔티티를 Dto로 변환해서 화면에 반환하게 되면 엔티티를 직접적으로 반환했을 때 발생하는 문제들을 방지할 수 있다.
하지만 위의 경우, N+1 문제가 발생하게 되어, 성능 상에 좋지 못한 부분을 보인다.
주문 객체를 조회하게 되면 우선, 주문 객체를 조회하는 쿼리문이 실행된다. 이때, 조회된 쿼리의 결과가 N개라고 가정하자. 이제, 각각의 주문 객체는 멤버, 배송과 같은 연관 필드를 가지기 때문에 각각에 대해서 다시 쿼리문이 실행되게 된다. 이처럼 1번의 조회를 통해 N개의 결과반환되고, N번의 조회를 다시 수행하게 되어 N+1 번의 쿼리를 수행을 통해 성능상에 문제가 발생하게 된다.
즉시로딩으로 한다고 해서, N+1 문제가 해결되는 것은 아니다. 단지 N+1 문제가 언제 발생하냐의 차이일뿐 즉시로딩이 해결책이 되지는 못한다.
자세한 내용은 jpa_성능최적화를 참고하자
이러한 문제를 해결하기 위해, jpql fetch join을 통해 연관된 필드를 한번에 가져오는 쿼리를 실행한다.
주문 조회 v3 (Dto + jpql fetch join)
@GetMapping("/api/v3/simple-orders")
public List<SimpleOrderDto> ordersV3() {
List<Order> orders= orderRepository.findAllWithMemberDelivery();
List<SimpleOrderDto> result=orders.stream()
.map(SimpleOrderDto::new)
.collect(Collectors.toList());
return result;
}
public List<Order> findAllWithMemberDelivery() {
return em.createQuery("select o from Order o"
+ " join fetch o.member m"
+ " join fetch o.delivery d", Order.class)
.getResultList();
}
jpql의 fetch join을 통해 연관된 필드를 한꺼번에 받아오도록한다.
주문 조회 v3 (Dto + jpql new constructor)
public List<SimpleOrderQueryDto> findOrderDtos() {
return em.createQuery("select new jpabook.jpashop.repository.SimpleOrderQueryDto(o.id,m.name,"
+ "o.orderDate, o.status, d.address)"
+ " from Order o"
+ " join o.member m"
+ " join o.delivery d", SimpleOrderQueryDto.class)
.getResultList();
}
@Data
public class SimpleOrderQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public SimpleOrderQueryDto(Long orderId,String name,LocalDateTime orderDate, OrderStatus orderStatus, Address address) {
this.orderId=orderId;
this.name=name;
this.orderDate=orderDate;
this.orderStatus=orderStatus;
this.address=address;
}
}
jpql의 new 연산을 통해 쿼리를 수행할때 Dto 객체 형태로 받아오는 것도 가능하다. 이렇게 하면 필요한 필드만 조회를 할 수 있기 때문에 엔티티를 조회할 때보다 성능을 높일 수 있다.
주문 조회(컬렉션)
기존의 Order 엔티티의 경우 OrderItem 리스트를 필드로 가지고 있다. 즉, 컬렉션을 가지고 있기 때문에 xxToMany 연관관계를 가지는 필드에 대한 고려가 필요하다.
v1: 엔티티 반환
@GetMapping("/api/v1/orders")
public List<Order> ordersV1() {
List<Order> orders = orderRepository.findAll(new OrderSearch());
for (Order order : orders) {
order.getMember().getName();
order.getDelivery().getAddress();
List<OrderItem> orderItems = order.getOrderItems();
for (OrderItem orderItem : orderItems) {
orderItem.getItem().getName();
}
}
return orders;
}
엔티티를 직접 반환하는 경우에는 Hibernate Module을 활용하여 Json 객체를 반환할 수 있도록 하면 되고, 추가적으로 각각의 컬렉션 내의 객체에 대해서는 초기화를 위해 위와 같이 반복문을 통해 각각의 객체를 초기화를 진행한다.
Result
[
{
"id": 1,
"member": {
"id": 1,
"name": "userA",
"address": {
"city": "서울",
"street": "1",
"zipcode": "1111"
}
},
"orderItems": [
{
"id": 1,
"item": {
"id": 1,
"name": "JPA Book1",
"categories": null,
"price": 10000,
"stockQuantity": 99,
"author": null,
"isbn": null
},
"orderPrice": 10000,
"count": 1,
"totalPrice": 10000
},
{
"id": 2,
"item": {
"id": 2,
"name": "JPA Book2",
"categories": null,
"price": 20000,
"stockQuantity": 98,
"author": null,
"isbn": null
},
"orderPrice": 20000,
"count": 2,
"totalPrice": 40000
}
],
"delivery": {
"id": 1,
"address": {
"city": "서울",
"street": "1",
"zipcode": "1111"
},
"status": "READY"
},
"orderDate": "2023-02-06T23:42:39.371864",
"status": "ORDER",
"totalPrice": 50000
},
{
"id": 2,
"member": {
"id": 2,
"name": "userB",
"address": {
"city": "전주",
"street": "2",
"zipcode": "2222"
}
},
"orderItems": [
{
"id": 3,
"item": {
"id": 3,
"name": "Spring Book1",
"categories": null,
"price": 20000,
"stockQuantity": 197,
"author": null,
"isbn": null
},
"orderPrice": 20000,
"count": 3,
"totalPrice": 60000
},
{
"id": 4,
"item": {
"id": 4,
"name": "Spring Book2",
"categories": null,
"price": 40000,
"stockQuantity": 296,
"author": null,
"isbn": null
},
"orderPrice": 40000,
"count": 4,
"totalPrice": 160000
}
],
"delivery": {
"id": 2,
"address": {
"city": "전주",
"street": "2",
"zipcode": "2222"
},
"status": "READY"
},
"orderDate": "2023-02-06T23:42:39.433866",
"status": "ORDER",
"totalPrice": 220000
}
]
위의 Member, Order 조회에서도 보앗듯, 엔티티를 직접적으로 반환하게 되면 민감한 정보가 그대로 노출된다는 문제점이 있고, 무엇보다도 공개 스펙인 API에 엔티티를 노출하게 됨에 따라 화면과 비즈니스 로직간에 연관관계가 형성되는 문제점이 발생하기 때문에 절대로 엔티티를 직접적으로 반환해서는 안된다.
v2: Dto 처리
엔티티를 직접적으로 반환하는 대신에 Dto를 만들어서 Dto 형태로 반환하는 것이 좋다.
이전에 SimpleOrderDto에서도 Dto 형태로 반환하는 것을 하였지만, 이번에는 Order와 OrderItem 간에 OneToMany 관계가 형성되어 있기 때문에 각각의 OrderItem에 대해서 OrderItemDto를 만들어서 이를 초기화하는 작업을 수행한다.
Dto 형태로 반환할때에는 Dto 내부에 객체에 대해서는 엔티티 형태가 아닌 객체 형태로 풀어서 저장해야한다.
Dtos
@Data
static class OrderDto {
private Long orderId;
private String name;
private LocalDateTime localDateTime;
private OrderStatus orderStatus;
private Address address;
private Result orderItems;
public OrderDto(Order order) {
this.orderId = order.getId();
this.name = order.getMember().getName();
this.localDateTime = order.getOrderDate();
this.orderStatus = order.getStatus();
this.address = order.getDelivery().getAddress();
//OrderItem은 list 형태로 가지고 있기 때문에, 리스트 형태로 반환하기 보다는 Result 객체를 만들어서 Result 객체 형태로 반환하여 추가적인 작업을 수행하기 편하도록 한다.
this.orderItems = new Result(order.getTotalPrice(),order.getOrderItems().stream()
.map(OrderItemDto::new)
.collect(Collectors.toList()));
}
}
@Data
static class OrderItemDto {
private String itemName;
private int orderPrice;
private int count;
public OrderItemDto(OrderItem orderItem) {
this.itemName = orderItem.getItem().getName();
this.orderPrice = orderItem.getOrderPrice();
this.count = orderItem.getCount();
}
}
@Data
@AllArgsConstructor
static class Result<T>{
int totalPrice;
T data;
}
Api Controller
@GetMapping("/api/v2/orders")
public List<OrderDto> ordersV2() {
List<Order> orders = orderRepository.findAll(new OrderSearch());
List<OrderDto> result = orders.stream()
.map(OrderDto::new) //OrderDto의 생성자 호출을 통해 OrderDto, OrderItemDto를 초기화한다.
.collect(Collectors.toList());
return result;
}
Result
[
{
"orderId": 1,
"name": "userA",
"localDateTime": "2023-02-06T23:42:39.371864",
"orderStatus": "ORDER",
"address": {
"city": "서울",
"street": "1",
"zipcode": "1111"
},
"orderItems": {
"totalPrice": 50000,
"data": [
{
"itemName": "JPA Book1",
"orderPrice": 10000,
"count": 1
},
{
"itemName": "JPA Book2",
"orderPrice": 20000,
"count": 2
}
]
}
},
{
"orderId": 2,
"name": "userB",
"localDateTime": "2023-02-06T23:42:39.433866",
"orderStatus": "ORDER",
"address": {
"city": "전주",
"street": "2",
"zipcode": "2222"
},
"orderItems": {
"totalPrice": 220000,
"data": [
{
"itemName": "Spring Book1",
"orderPrice": 20000,
"count": 3
},
{
"itemName": "Spring Book2",
"orderPrice": 40000,
"count": 4
}
]
}
}
]
결과적으로 Dto 형태로 반환하여 원하는 정보만 출력될 수 있게끔 설정한다. 하지만, 위의 Dto 방식의 반환의 경우 DB 쿼리가 많이 호출된다는 문제점이 발생한다.
- Order 객체를 조회하기 위해 한번의 쿼리가 수행된다.
select
o1_0.order_id,
o1_0.delivery_id,
o1_0.member_id,
o1_0.order_date,
o1_0.status
from
orders o1_0
join
member m1_0
on m1_0.member_id=o1_0.member_id
where
1=1 fetch first ? rows only
- 각 Order 객체에 대해 정보(Member, Delivery,OrderItem)를 조회하기 위해 1번에서 반환된 Order의 갯수만큼 쿼리가 수행된다.
/* member 조회 */
select
m1_0.member_id,
m1_0.city,
m1_0.street,
m1_0.zipcode,
m1_0.name
from
member m1_0
where
m1_0.member_id=?
/* delivery 조회 */
select
d1_0.delivery_id,
d1_0.city,
d1_0.street,
d1_0.zipcode,
d1_0.status
from
delivery d1_0
where
d1_0.delivery_id=?
/* orderitem 조회 */
select
o1_0.order_id,
o1_0.order_item_id,
o1_0.count,
o1_0.item_id,
o1_0.order_price
from
order_item o1_0
where
o1_0.order_id in(?,?)
- 각 OrderItem에 등록된 Item 조회를 위해 2번에서 반환된 OrderItem 갯수만큼 실행된다.
select
i1_0.item_id,
i1_0.dtype,
i1_0.name,
i1_0.price,
i1_0.stock_quantity,
i1_0.artist,
i1_0.etc,
i1_0.author,
i1_0.isbn,
i1_0.actor,
i1_0.director
from
item i1_0
where
i1_0.item_id=?
즉, 총 O(1+n+m) 만큼의 매우 많은 쿼리 수행을 통해 성능면에서 떨어지는 부분이 존재한다.
v3: fetch join
위의 N+1(실제로는 N+1 보다 더한 문제) 쿼리 문제를 해결하기 위해 Fetch join 형태로 모든 연관된 필드를 한번에 받아오는 쿼리 수행을 통해 쿼리 요청 횟수를 줄인다.
Api Controller
@GetMapping("/api/v3/orders")
public List<OrderDto> ordersV3() {
List<Order> orders = orderRepository.findAllWithItems();
List<OrderDto> result = orders.stream()
.map(OrderDto::new)
.collect(Collectors.toList());
return result;
}
findAllWithItems
public List<Order> findAllWithItems() {
return em.createQuery("select distinct o from Order o"
+ " join fetch o.member m"
+ " join fetch o.delivery d"
+ " join fetch o.orderItems oi"
+ " join fetch oi.item i", Order.class)
/*.setFirstResult(0)
.setMaxResults(100)*/
.getResultList();
}
위와 같이 fetch join을 통해 아래와 같이 쿼리가 총 1번만 수행되는 것을 확인할 수 있다.
select
distinct o1_0.order_id,
d1_0.delivery_id,
d1_0.city,
d1_0.street,
d1_0.zipcode,
d1_0.status,
m1_0.member_id,
m1_0.city,
m1_0.street,
m1_0.zipcode,
m1_0.name,
o1_0.order_date,
o2_0.order_id,
o2_0.order_item_id,
o2_0.count,
i1_0.item_id,
i1_0.dtype,
i1_0.name,
i1_0.price,
i1_0.stock_quantity,
i1_0.artist,
i1_0.etc,
i1_0.author,
i1_0.isbn,
i1_0.actor,
i1_0.director,
o2_0.order_price,
o1_0.status
from
orders o1_0
join
member m1_0
on m1_0.member_id=o1_0.member_id
join
delivery d1_0
on d1_0.delivery_id=o1_0.delivery_id
join
order_item o2_0
on o1_0.order_id=o2_0.order_id
join
item i1_0
on i1_0.item_id=o2_0.item_id
하지만, 위의 collection fetch join 방식으로 query를 수행하게 되면 paging이 안된다는 문제점이 있다.
원래, 조회되는 Order의 갯수가 2개인데, 위의 방식을 통해 fetch join을 수행하게 되면 아래와 같이 4개가 조회되는 것을 확인할 수 있다.

기존의 Order 객체는 각각 2개의 OrderItem을 가지는 형태인데, 이를 fetch join을 수행하게 되면서 4개의 행으로 뻥튀기 되는 현상이 발생하게 되었다. 즉, 기준이 Order에서 OrderItem으로 변경됨에 따라 페이징이 불가능하게 된다.
collection fetch join에 대해서는 db 자체적으로 처리하지 못하도록 하지만 실제로 application을 실행해보면 paging이 동작하는 것을 확인할 수 있다.위의 findAllWithItems 메소드에서 paging 기능을 설정해서 실행해보면 console 창에 Warning이 뜨는 것을 확인할 수 있다.
WARN 28712 --- [nio-8080-exec-1] org.hibernate.orm.query : HHH90003004: firstResult/maxResults specified with collection fetch; applying in memory
이는 memory 상에서 필요한 객체를 받아서 페이징 처리를 진행하는 것이기 때문에 대량의 데이터를 처리해야되는 경우에 대해서는 메모리 부족현상이 발생할 수도 있기 때문에 collection fetch join에서는 페이징 처리를 하지 않도록 한다.
v3.1: batch fetch join
위의 페이징이 안되는 문제를 처리하기 위해서는, collection에 대해 fetch join을 수행해서는 안된다. ToOne에 대해서는 fetch join을 하더라도 결과 행수의 차이가 없기 때문에 상관이 없다.
그렇다면 컬렉션은 그냥 지연 로딩 + 초기화를 통해서만 해야되나?? BatchSize을 활용하면 페이징이 가능하면서 v2 방식보다는 성능이 뛰어나도록 처리하는 것이 가능하다.
application.yaml
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 1000
Api Controller
@GetMapping("/api/v3.1/orders")
public List<OrderDto> ordersV3_paging(
@RequestParam(value= "offset",defaultValue = "0") int offset,
@RequestParam(value = "limit",defaultValue = "100") int limit
) {
List<Order> orders = orderRepository.findAllWithMemberDelivery(offset,limit);
List<OrderDto> result = orders.stream()
.map(OrderDto::new)
.collect(Collectors.toList());
return result;
}
findAllWithMemberDelivery
public List<Order> findAllWithMemberDelivery(int offset, int limit) {
return em.createQuery("select o from Order o"
+ " join fetch o.member m"
+ " join fetch o.delivery d", Order.class)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
ToOne 관계를 가지는 필드에 대해서는 fetch join으로 처리하고, 컬렉션의 경우 지연 로딩으로 설정하여 나중에 필요할때 쿼리를 요청하도록 한다. 이렇게 하면 v2와 같아보이지만, v3.1의 핵심은 @BatchSize에 있다.
아래의 sql을 확인해보면 order 조회를 위한 쿼리 1개 + orderitem에 대한 item 조회를 위해 쿼리가 1번 실행되는 것을 확인할 수 있다. BatchSize 설정을 통해 in 절을 활용하여 필요한 객체들을 한번에 가져오는 작업을 실행하는 것이다. 이렇게 하면 단 2번의 쿼리를 수행을 통해 원하는 객체들을 가져오는 것이 가능하다. 물론 한번에 가져올 수 있는 최대 크기는 1000개 이기 때문에 1000개를 넘어가는 객체에 대해서는 요청되는 쿼리의 갯수가 증가할 수 있다.
/* order 조회 */
select
o1_0.order_id,
o1_0.order_item_id,
o1_0.count,
o1_0.item_id,
o1_0.order_price
from
order_item o1_0
where
o1_0.order_id in(?,?)
/* orderitem 조회*/
select
i1_0.item_id,
i1_0.dtype,
i1_0.name,
i1_0.price,
i1_0.stock_quantity,
i1_0.artist,
i1_0.etc,
i1_0.author,
i1_0.isbn,
i1_0.actor,
i1_0.director
from
item i1_0
where
i1_0.item_id in(?,?,?,?)
batch fetch join을 통해 v2에 비해 처리되는 쿼리의 갯수를 줄였을 뿐만 아니라, v3에서는 collection fetch join을 통해 많은 중복이 발생하게 되는데, v3.1의 경우는 그러한 중복도 발생하지 않게 된다.
v4: jpa에서 dto 형태로 쿼리 수행
이제는, 직접적으로 jpql에서 Dto 형태로 받아오는 방식을 확인해보자
Api Controller
@GetMapping("/api/v4/orders")
public List<OrderQueryDto> ordersV4() {
return orderQueryRepository.findOrderQueryDtos();
}
OrderQueryRespository
public List<OrderQueryDto> findOrderQueryDtos() {
List<OrderQueryDto> orders = findOrders();
orders.stream().forEach((o)->o.setOrderItems(findOrderItems(o.getOrderId())));
return orders;
}
private List<OrderQueryDto> findOrders() {
return entityManager.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderQueryDto(o.id,m.name,o.orderDate,o.status,d.address)"
+ " from Order o"
+ " join o.member m"
+ " join o.delivery d", OrderQueryDto.class)
.getResultList();
}
private List<OrderItemQueryDto> findOrderItems(long orderId) {
return entityManager.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id,i.name,oi.orderPrice,oi.count)"
+ " from OrderItem oi"
+ " join oi.item i"
+ " where oi.order.id = :orderId",OrderItemQueryDto.class)
.setParameter("orderId",orderId)
.getResultList();
}
Order 객체를 먼저 받아온 다음에, Order 객체에 등록되는 OrderItem에 대한 처리를 진행한다.
화면과 직접적으로 연관되어 처리하는 쿼리에 대해서는 별도의 패키지를 묶어서 처리하는 것이 유지보수 관점에서 좋다.
v5: v4 최적화
v4의 문제점
/* order 객체 조회 */
select
o1_0.order_id,
m1_0.name,
o1_0.order_date,
o1_0.status,
d1_0.city,
d1_0.street,
d1_0.zipcode
from
orders o1_0
join
member m1_0
on m1_0.member_id=o1_0.member_id
join
delivery d1_0
on d1_0.delivery_id=o1_0.delivery_id
/* item에 대한 조회*/
select
o1_0.order_id,
i1_0.name,
o1_0.order_price,
o1_0.count
from
order_item o1_0
join
item i1_0
on i1_0.item_id=o1_0.item_id
where
o1_0.order_id=?
select
o1_0.order_id,
i1_0.name,
o1_0.order_price,
o1_0.count
from
order_item o1_0
join
item i1_0
on i1_0.item_id=o1_0.item_id
where
o1_0.order_id=?
v4 방식을 보면 눈에 띄는 점이 한가지 존재하는데, 바로 1+N 문제가 발생한다는 점이다. Order 객체 조회를 위해 쿼리가 1번 실행되게 되며, 각각의 OrderItem에 대한 처리를 위해 N번(정확히는 Order 객체의 갯수) 만큼 실행된다. 이와 같은 문제를 처리하기 위해 v3.1에서 활용한 BatchFetch를 응용해서 최적화를 진행한다.
Api Controller
@GetMapping("/api/v5/orders")
public List<OrderQueryDto> ordersV5() {
return orderQueryRepository.findAllByDto_optimization();
}
OrderQueryRepository
public List<OrderQueryDto> findAllByDto_optimization() {
//Order 객체를 조회하는 작업 --> 위의 v4와 동일
List<OrderQueryDto> orders = findOrders();
//위의 Order 객체에 대응되는 OrderItem를 찾기 위해 Order 객체의 id와 OrderItem 객체를 mapping한다.
Map<Long, List<OrderItemQueryDto>> results = findOrderItemMap(toOrderIds(orders));
//각 Order 객체에 대한 OrderItem을 초기화한다.
orders.stream().forEach((o) -> o.setOrderItems(results.get(o.getOrderId())));
return orders;
}
//각 주문 객체에 대해, id 목록을 반환하는 메소드
private List<Long> toOrderIds(List<OrderQueryDto> orders) {
return orders.stream()
.map((o) -> o.getOrderId())
.collect(Collectors.toList());
}
private Map<Long, List<OrderItemQueryDto>> findOrderItemMap(List<Long> orderIds) {
List<OrderItemQueryDto> orderItems = entityManager.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderItemQueryDto(oi.order.id,i.name,oi.orderPrice,oi.count)"
+ " from OrderItem oi"
+ " join oi.item i"
+ " where oi.order.id in :orderIds", OrderItemQueryDto.class)
.setParameter("orderIds", orderIds)
.getResultList();
//Order와 연관된 OrderItem을 모두 찾은 다음에, Order id에 대해 grouping을 설정한다.
return orderItems.stream().collect(groupingBy(OrderItemQueryDto::getOrderId));
}
Order 객체 조회를 위한 쿼리 1번 + OrderItem 객체 조회를 위한 쿼리 1번을 수행해서 application에 이들을 서로 연관시키는 작업을 진행한다.
/* order 조회 */
select
o1_0.order_id,
m1_0.name,
o1_0.order_date,
o1_0.status,
d1_0.city,
d1_0.street,
d1_0.zipcode
from
orders o1_0
join
member m1_0
on m1_0.member_id=o1_0.member_id
join
delivery d1_0
on d1_0.delivery_id=o1_0.delivery_id
/* orderitem 조회 */
select
o1_0.order_id,
i1_0.name,
o1_0.order_price,
o1_0.count
from
order_item o1_0
join
item i1_0
on i1_0.item_id=o1_0.item_id
where
o1_0.order_id in(?,?)
v6: v5 최적화
v5에서는 총 2번의 쿼리가 요청되었지만, 더 최적화해서 1번의 쿼리만 실행되도록 할 수 있다.
Api Controller
@GetMapping("/api/v6/orders")
public List<OrderQueryDto> ordersV6() {
List<OrderFlatDto> flats = orderQueryRepository.findAllByDto_flat();
return flats.stream()
.collect(groupingBy(o -> new OrderQueryDto(o.getOrderId(),
o.getName(), o.getOrderDate(), o.getOrderStatus(), o.getAddress()),
mapping(o -> new OrderItemQueryDto(o.getOrderId(),
o.getItemName(), o.getOrderPrice(), o.getCount()), toList())
)).entrySet().stream()
.map(e -> new OrderQueryDto(e.getKey().getOrderId(),
e.getKey().getName(), e.getKey().getOrderDate(), e.getKey().getOrderStatus(),
e.getKey().getAddress(), e.getValue()))
.collect(toList());
}
OrderQueryRepository
public List<OrderFlatDto> findAllByDto_flat() {
return entityManager.createQuery(
"select new jpabook.jpashop.repository.order.query.OrderFlatDto(o.id,m.name,o.orderDate,o.status,d.address,i.name,oi.orderPrice,oi.count)"
+ " from Order o"
+ " join o.member m"
+ " join o.delivery d"
+ " join o.orderItems oi"
+ " join oi.item i", OrderFlatDto.class)
.getResultList();
}
Order+OrderItem 1개 형태의 flat한 데이터를 받아서 이를 적절히 처리해서 Order 객체를 만들어내는 작업을 수행한다.
select
o1_0.order_id,
m1_0.name,
o1_0.order_date,
o1_0.status,
d1_0.city,
d1_0.street,
d1_0.zipcode,
i1_0.name,
o2_0.order_price,
o2_0.count
from
orders o1_0
join
member m1_0
on m1_0.member_id=o1_0.member_id
join
delivery d1_0
on d1_0.delivery_id=o1_0.delivery_id
join
order_item o2_0
on o1_0.order_id=o2_0.order_id
join
item i1_0
on i1_0.item_id=o2_0.item_id
총 1번의 쿼리 요청으로 모든 Order 객체를 받아오는데 성공하였지만, 추가되는 코드의 양이 많고, application에서 처리해야되는 작업이 많아지게 된다.
Api Optimization plan
성능과 코드 복잡도 간에 trade-off가 발생하게 된다. 따라서 서로 적정 수준을 유지하는 것이 중요하다.
JPA를 활용하여 DB로의 데이터를 요청하는 방식에는 크게 2가지 방식이 존재한다.
- entity를 조회하는 방식
- Dto 형태로 조회하는 방식
entitiy를 조회하게 되면, @BatchSize, fetch join, hibernate batch, 등 jpa에서 성능 최적화를 위해 많은 부분을 자동화해주는 부분이 많아 코드의 복잡도를 낮출 수 있다.
반면, Dto 조회 방식의 경우 직접적으로 쿼리를 설계해야하는 되는 부분이 있어, 코드의 복잡도가 증가한다는 부분이 있다.
그래서, Api를 설계할 때 DB 접근 방식으로 우선적으로 entity 조회 방식을 선호한다. 아래의 우선순위를 고려해서 DB 조회를 진행한다.
-
- entity 조회 방식
-
- fetch join을 통한 쿼리 수 최적화
-
- 컬렉션 최적화
- 페이징 필요시: batch fetch join 활용
- 페이징 필요하지 않을 경우: collection fetch join 활용
-
- entity 조회 방식
-
- Dto 조회
-
- NativeSQl, JDBCTemplate
References
link: inflearn
link:jpa
link:thymeleaf
link: springboot3
댓글남기기