
Java Spring Advanced part 7
Bean Postprocessor
Spring Bean LifeCycle
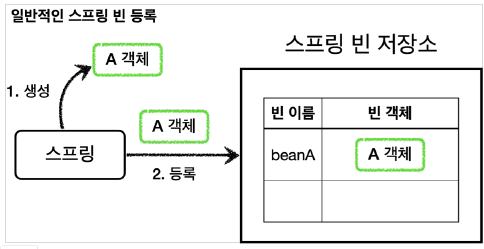
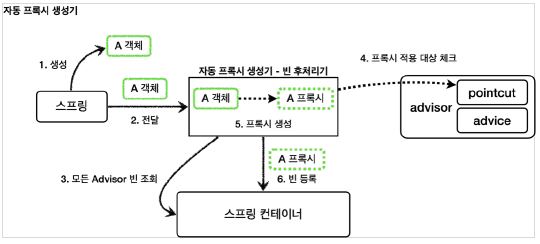
기존의 Spring Bean 생성 과정은 위와 같이 동작하게 된다. 하지만, Spring Container에 Spring Bean을 등록하기 전에 아래와 같이 빈후처리기가 동작하게 되면서, Spring Bean에 대한 조작을 수행하게 된다.
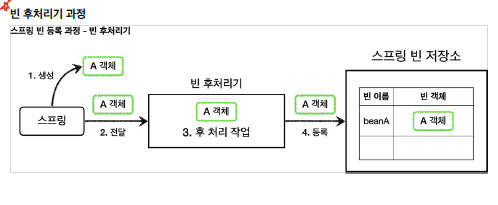
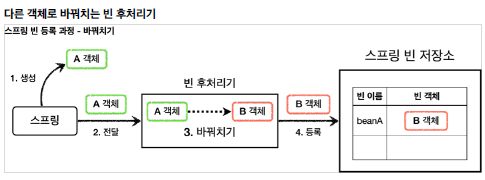
빈 후처리 과정 중에, 해당 빈 객체에 대한 조작을 수행할 수 있고, 완전히 다른 객체로 대체하는 것도 가능하다.
Practice
Non-Post Processing
Bean PostProcesing을 이용해서 Spring Bean에 대한 조작을 수행보자
@Slf4j
@Configuration
static class BasicConfig{
@Bean(name= "beanA")
public A a(){
return new A();
}
}
@Slf4j
static class A{
public void helloA(){
log.info("hello A");
}
}
@Slf4j
static class B{
public void helloB(){
log.info("hello B");
}
}
위와 같이 config를 구성하게 되면 A 클래스가 Spring Container에 등록되게 된다.
@Test
void basicConfig() {
ApplicationContext ac = new AnnotationConfigApplicationContext(BasicConfig.class);
A a = ac.getBean(A.class);
a.helloA();
//assertThrows(NoSuchBeanDefinitionException.class, () -> ac.getBean(B.class));
assertThatThrownBy(() -> ac.getBean(B.class)).isInstanceOf(NoSuchBeanDefinitionException.class);
}
Bean Post Processing
이번에는 후처리기를 이용해서 A 객체로 등록한 Spring Bean을 B 객체로 바꿔보자
Bean PostProcessor Interface
public interface BeanPostProcessor {
Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException
Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException
}
빈 후처리기는 위의 interface의 메소드를 구현시키면 된다.
initialization는 @PostConstruct를 기준 삼아서 말하는 것이다. beforeInitialization은 @PostConstruct 이전에 실행되는 것을 의미하고
afterInitialization은 @PostConstruct 이후에 실행되는 것을 의미한다.
매개변수로 전달되는 bean, beanName은 Spring Container에 등록되기 전의 Spring Bean 객체와 bean 이름이다.
@Slf4j
@Configuration
static class BeanPostProcessorConfig{
@Bean(name= "beanA")
public A a(){
return new A();
}
@Bean
public AToBPostProcessor helloPostProcessor(){
return new AToBPostProcessor();
}
}
@Slf4j
static class AToBPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
log.info("beanName: {}, bean : {}", beanName, bean);
if(bean instanceof A){
return new B();
}
return bean;
}
}
후 처리기를 생성해서, 후처리기를 Spring Bean으로 등록해서, 후처리기가 실행될 수 있도록 한다.
위와 같이, A 객체에 대해서 B 객체로 대체하게 되면 아래와 같이 Spring Container에 요청을 수행하게 되면 B 객체가 반환되게 된다.
@Test
void basicConfig() {
ApplicationContext ac = new AnnotationConfigApplicationContext(BeanPostProcessorConfig.class);
B b = ac.getBean(B.class);
b.helloB();
//assertThrows(NoSuchBeanDefinitionException.class, () -> ac.getBean(A.class));
assertThatThrownBy(() -> ac.getBean(A.class)).isInstanceOf(NoSuchBeanDefinitionException.class);
}
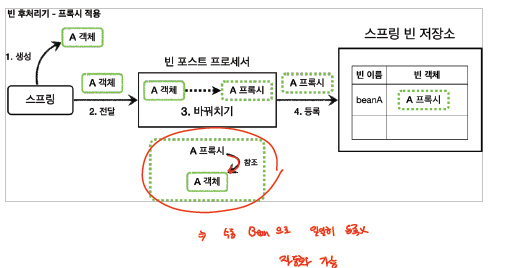
위의 예제를 통해 알 수 있는 것은, Spring Bean을 생성한 이후에, Bean Postprocessor가 동작하게 되며, Spring Container에 올리기 전에 동작하는 것을 알 수 있다. 따라서, 우리는 여기에 프록시 객체로 대체하는 과정을 후처리 과정으로 등록하게 되면, Spring Bean를 생성한 이후에, 자동으로 프록시 객체로 만드는 것을 진행할 수 있다.
또한, 이렇게 Bean 생성 이후에 적용되기 때문에, Component scan 과정을 통해 생성된 Spring Bean에도 bean post processing 과정이 적용된다.
Apply Bean Post Processor to Application
Bean Post Processor
@Slf4j
public class PackageLogTracePostProcessor implements BeanPostProcessor {
private final String basePackage;
private final Advisor advisor;
public PackageLogTracePostProcessor(String basePackage, Advisor advisor) {
this.basePackage = basePackage;
this.advisor = advisor;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
log.info("beanName: {}, bean:{}", beanName, bean.getClass());
String packageName = bean.getClass().getPackageName();
//basePackage에 해당하지 않는 bean에 대해서는 프록시를 생성하지 않는다.
if (!packageName.startsWith(basePackage)) {
return bean;
}
ProxyFactory proxyFactory = new ProxyFactory(bean);
proxyFactory.addAdvisor(advisor);
Object proxy = proxyFactory.getProxy();
log.info("create proxy target:{}, proxy:{}", bean.getClass(), proxy.getClass());
return proxy;
}
}
위와 같이, 특정 package에 있는 Spring Bean을 대상으로 Proxy class을 만드는 과정을 진행하게 된다.
마지막으로, 위의 Bean Post Processor을 Spring Bean으로 등록해주게 되면, 모든 과정이 끝난다.
@Configuration
@Slf4j
@Import({AppV1Config.class, AppV2Config.class})
public class BeanPostProcessorConfig {
@Bean
public PackageLogTracePostProcessor logTracePostProcessor(LogTrace trace) {
return new PackageLogTracePostProcessor("hello.proxy.app",getAdvisor(trace));
}
private Advisor getAdvisor(LogTrace logTrace) {
NameMatchMethodPointcut pointcut = new NameMatchMethodPointcut();
pointcut.setMappedNames("request*", "order*", "save*");
LogTraceAdvice advice = new LogTraceAdvice(logTrace);
return new DefaultPointcutAdvisor(pointcut, advice);
}
}
이렇게, Bean Post Processort을 통한 Proxy 생성 과정을 수행하게 되면서, 이제는 ProxyFactory, Advice 구성과 같이 무수히 많은 설정 파일을 관리할 필요 없이, 오직 위의 하나의 설정 파일로 모든 Spring Bean에 대해 프록시를 구성할 수 있게 되었다. –> SRP 원칙을 더욱 더 철저히 지키게 된것이다.
Spring Bean Post Processor
하지만, 여태껏 Spring을 사용하면서, Spring이 가지는 장점은 항상 여기서 그치지 않는다. Spring은 이러한 Bean Post Processor 이미 내부적으로 구현해놓았다.
gradle
implementation 'org.springframework.boot:spring-boot-starter-aop'
위의 dependency를 추가하게 되면, AnnotationAwareAspectJAutoProxyCreator라고 하는 Spring Bean Post Processor가 등록되게 된다. 이는, 자동으로 Spring Bean으로 등록된 객체에 대해서 프록시 객체를 만들어주는 후 처리기이다.
그러면, 모든 객체에 대해서 프록시를 만들게 될까?? –> 이는 Advisor에 따라가게 된다.
이전에 Advisor는 PointCut과 Advice로 이루어져 있음을 배우게 되었는데, PointCut은 Advice를 적용할 메소드를 지정할 수 있는 필터링 기능을 제공하였다.
하지만, 추가로, 프록시 객체를 만들지 여부를 PointCut을 이용해서 결정할 수 있다.즉, 위의 Bean Post Processor은 모든 메소드에 대해서 PointCut을 통해 검증하면서 해당 메소드를 가지는 Spring Bean에 대해서 Proxy를 구성할지 여부를 판단할 수 있는 것이다.
Config
@Configuration
@Slf4j
@Import({AppV1Config.class, AppV2Config.class})
public class AutoProxyConfig {
//@Bean
public Advisor advisor1(LogTrace logTrace) {
NameMatchMethodPointcut pointcut = new NameMatchMethodPointcut();
pointcut.setMappedNames("request*", "order*", "save*");
LogTraceAdvice advice = new LogTraceAdvice(logTrace);
return new DefaultPointcutAdvisor(pointcut, advice);
}
}
위와 같이 pointcut을 설정하고, 해당 Advisor를 Spring Bean으로 등록하게 되면, Spring 내부에서 Bean으로 등록된 Advisor를 모두 분석해서 pointcut에 맞는 Spring Bean을 생성하게 된다.
하지만, 위와 같이 메소드 이름에 대해서 pointcut으로 지정하게 되면 아래의 Spring Bean에 대해서도 프록시 객체가 생성되게 된다.
EnableWebMvcConfiguration.requestMappingHandlerAdapter()
EnableWebMvcConfiguration.requestMappingHandlerAdapter() time=63ms
그래서, 조금 더 세밀한 pointcut을 구성할 필요가 있다.
public Advisor advisor2(LogTrace logTrace) {
AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();
pointcut.setExpression("execution(* hello.proxy.app..*(..))");
LogTraceAdvice advice = new LogTraceAdvice(logTrace);
return new DefaultPointcutAdvisor(pointcut, advice);
}
이때, AspectJExpressionPointCut을 이용해서 AspectJ 방식으로 pointcut을 구성한다. 위와 같이, pointcut을 구성하게 되면 hello.proxy.app 패키지 아래에 있는 클래스에 대해서만 프록시를 생성하게 된다.
하지만, 우리는 로그를 출력하지 않는(부가 기능을 수행하지 않는) 메소드가 존재한다. 하지만, 위와 같이 package 이름에 대해서 Pointcut을 지정하게 되면, no-log 메소드를 구현하고 있는 Controller가 Spring Bean으로 등록되게 되면서, 로그를 출력하게 된다.
@Bean
public Advisor advisor3(LogTrace logTrace) {
AspectJExpressionPointcut pointcut = new AspectJExpressionPointcut();
pointcut.setExpression("execution(* hello.proxy.app..*(..)) && !execution(* hello.proxy.app..noLog(..))");
LogTraceAdvice advice = new LogTraceAdvice(logTrace);
return new DefaultPointcutAdvisor(pointcut, advice);
}
이때 위와 같이, Package name을 통한 필터링에 추가적으로 no-log 메소드는 실행되지 않도록 pointcut을 구성한다.
Single Proxy, Multi Advisors
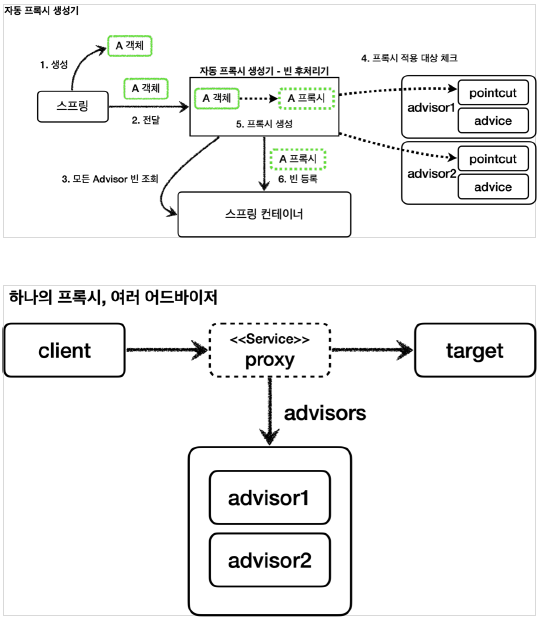
여기서 중요한 점은, 프록시는 반드시 한개만 생성되는 것이다.
가령, 여러 개의 advisor을 등록해 놓고, 여러 개의 advisor을 만족한다고 해서 여러 개의 프록시가 생성되는 것은 아니다. 이는, 프록시가 여러개의 advisor을 가지고 있을 수 있기 때문이다.
References
link: inflearn
link:spring_advanced
댓글남기기