
HSS System
CDP2_RDF_Platform
Description
본 프로젝트는 RDF data에 대한 최적화된 질의 기능을 제공해주는 Data Platform 이다. Apache jena library을 기반으로 Memory와 SSD을 결합한 Hybrid Storage 구조를 통해 빠른 질의 처리 서비스를 제공한다.
Collaborators
- 정제현 JehyunJung jhyun9152@naver.com
- 우정민 Jeongmin Woo - jeongmoon94@gmail.com
- 이인섭 dldlstjq - inseob111@naver.com
- 이승진 Leeseungjin - leetmdwls@naver.com
Motivation
- Hybrid Storage System
- SSD와 같은 flash memory의 경우 기존의 HDD와 같은 magnetic disk 방식의 data storage system에 비해서 높은 I/O 성능을 보여준다. 이는, HDD의 기계적인 회전을 통한 sequential search 방식을 전기적인 신호 방식을 활용한 random access 방식으로 대체하면서 생겨난 결과이다.
- 하지만, 이러한 flash memory 또한 결점이 있는데, 바로 Update-Out-Place 방식의 쓰기연산을 진행한다는 것이다. 기존의 영역에 덮어쓰는 형태인 Update-In-Place 구조와는 달리, 데이터를 쓰기 연산을 진행함에 있어, 블록 단위의 포맷을 한 후, 메모리에 데이터를 쓸 수 있다.
- flash memory의 느린 쓰기 연산을 개선 시킨 것이 바로, 3DXPoint와 같은 NVM(Non Volatile Memory)이다. 매우 빠른 I/O 처리속도를 보여주며, 데이터 단위가 적은 연산을 batch execution 할때 뛰어난 성능을 보여준다. 하지만, 이러한 NVM 메모리는 용량 대비 가격이 비싸기 때문에 비교적 가격이 싼 flash memory와 결합해서 Hybrid Storage 형태를 구성해서 이용한다.
- Hot Cold Data Clustering
- 특정 데이터에 있어서 자주 접근(이용)되는 데이터가 있는데, 이를 Hot Data, 상대적으로 덜 이용되는 데이터는 Cold Data라고 한다.
- Hybrid Storage System에서 데이터를 효율적으로 저장하기 위해, Hot Data의 경우 빠른 I/O 가능한 NVM 메모리에, Cold Data는 비교적 느린 flash memory에 저장하므로써 Hot Data에 대한 질의를 빠르게 처리할 수 있다. 이를 통해, NVM 메모리에 준하는 성능과 flash memory의 용량을 활용할 수 있다.
Contents
- Web application
- Interface for user
- Hybrid Storage Server
- API codes for fuseki-server access
- connect
- update, delete, switch data type
Development Environment
- jdk version >= 1.8
- apache tomcat 9.0
- mysql 5.7.30
- Anaconda
- Clustering-related libraries
- Matplotlib
- scikit-learn
- pandas
- numpy
Term Descriptions
RDF Data
URI 방식으로 존재하는 웹 상의 데이터 간의 상이한 메타데이터를 통합하기 위한 공통적인 규격으로 표현한 것이다. 이러한 RDF 데이터는 Subject, Predicate, Object을 가지는 rdf triple 구조를 지닌다.
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'
>
<rdf:Description rdf:nodeID="A0">
<vcard:Family>Smith</vcard:Family>
<vcard:Given>John</vcard:Given>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/JohnSmith/'>
<vcard:FN>John Smith</vcard:FN>
<vcard:N rdf:nodeID="A0"/>
</rdf:Description>
</rdf:RDF>
위와 같은 구조를 가지는 RDF 데이터는 아래와 같은 그래프로 표현된다.
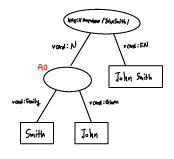
기존에 데이터 기반의 웹을 표현하기 위한 구체적인 방법으로, 웹 상에 존재하는 자원에 대해 URI를 부여하고, 각각의 자원들을 Link를 통해 서로 연결하여 제공하는 상호 연결형 웹을 의미한다. 궁극적으로 이렇게 uri를 통해 메타데이터를 연결하여 서로 의미와 연관성을 가지는 시맨틱 웹을 구성하는 것의 기본이 되는 것이 바로 데이터 기반의 웹을 생성하는 것이다. 웹 상의 데이터를 표현할 때, 의미론적 요소를 부여하여 웹 상의 자원에 대한 크롤링/인덱싱을 효율적으로 하고자 한다.
LOD를 데이터를 활용하면 누구나 쉽게 웹 상의 데이터를 접근할 수 있고, RDF 형태의 공통화된 규격을 통해 제공되는 LOD 데이터를 통해 어떠한 형태로도 활용될 수 있다는 장점이 있다.
현재, Wikipedia, DBpedia, google에서는 이미 데이터를 LOD 형태로 표현하여 제공하고 있는데, 이러한 LOD 데이터 내의 RDF Triple 이미 수십억개에 다달하는 어마마한 크기를 가지고 있다. 이러한 LOD 데이터에 대해 효과적으로 질의를 처리하는 시스템을 개발하고자하는 것이 이번 프로젝트의 핵심 과제였다.
Web Page info
Main Page
Sign In 버튼을 클릭하게 되면 로그인 창으로 넘어가게 된다.
Signin page
아이디와 패스워드 입력을 통해 로그인이 가능하다
Sign Up 버튼을 클릭하게 되면 회원가입 창으로 넘어간다.
Signup page
이름, 아이디, 패스워드를 입력하고 Sign Up 버튼 클릭을 통해 회원가입이 가능하다.
Data manage page
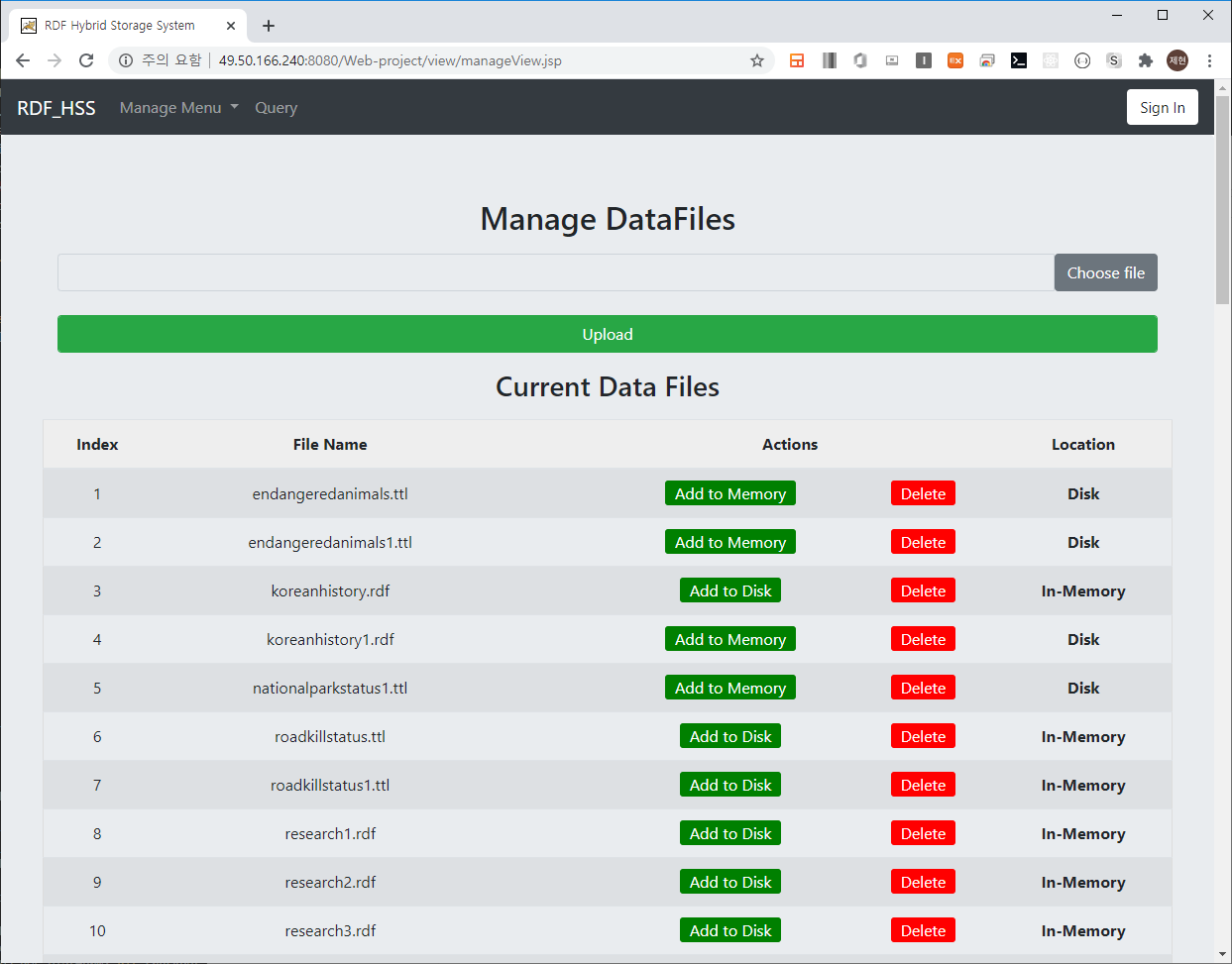
RDF Dataset을 관리하는 화면이다.
기능
- 파일 업로드
- 메모리/디스크 추가
- 파일 삭제 기능
Maching Learning
Models
Classifiers=[
DecisionTreeClassifier(),
LinearDiscriminantAnalysis(),
QuadraticDiscriminantAnalysis(),
GaussianNB(),
GaussianProcessClassifier(kernel=1.0*RBF(1.0)),
ExtraTreesClassifier(),
RidgeClassifier(),
KNeighborsClassifier(n_neighbors = 5)
]
Results
Acccuracy
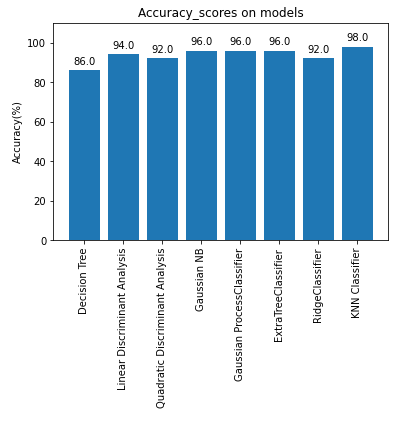
최대 98%의 정확도로 Hot/Cold Dataset을 분류하는 모델을 이용해서 Classification을 진행한다.
Classification Results
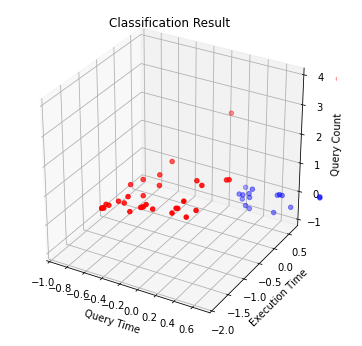
Hot은 빨간색으로, Cold는 파란색으로 표현하도록해서 Classification을 수행한 결과 위와 같이 Hot/Cold가 분류 것을 확인할 수 있다.
Query Execution Speed Enhancements

약 30%의 쿼리 수행 속도 증가를 확인할 수 있습니다.
댓글남기기