
MongoDB 5
Map Reduce
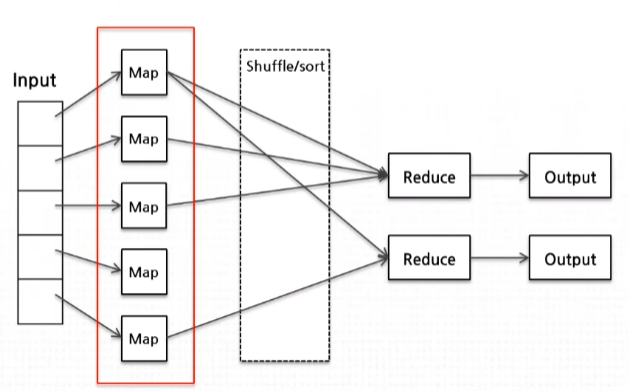
- 대용량 데이터에 대해 여러 대의 하드웨어에 분산해서 작업을 수행하는 방식을 의미한다. 분산 처리를 통해 빠른 작업 수행이 가능하다.
- 데이터를 분산하여 연산하고 다시 합치는 기술, 사용자(개발자)는 map/reduce를 설계하여 원하는 작업을 수행시키면된다.
- 분할된 조각이 작으면 작을 수록 분산 처리의 이점이 증가하지만, 과도하게 작은 경우 오히려 맵 생성을 위한 오버헤드가 증가한다.
Map Reduce vs RDBMS
| RDBMS | Map Reduce | |
|---|---|---|
| 데이터 크기 | 기가바이트 | 페타바이트 |
| 액세스 | 대화형 + 일괄처리 | 일괄처리 |
| 업데이트 | 여러 번 읽고 쓰기 | 한번 쓰고, 여러 번 읽기 |
| 구조 | 고정 스키마 | 동적 스키마 |
| 무결성 | 높음 | 낮음 |
| 확장성 | 비선형 | 선형 |
기존에 RDBMS에서 해결하기 어렸원던 부분들을 보완하는 방향으로 Map Reduce를 활용한다. Hadoop과 같은 Map Reduce 기반의 대용량 처리를 통해 일괄 처리가 요구되는 작업들을 수행한다.
Hadoop
구성 요소
- client: 데이터 송수신을 요청하는 어플리케이션
- namenode: hdfs 전체 시스템을 제어
- datanode: 데이터를 저장하는 서버 역할
처리 원칙
- block size: 파일을 저장하는 단위(64MB or 128MB)
- replication: 블록을 여러 노드에 복제해서 저장
hdfs 상에서 파일 전송 과정
- 저장하고자 하는 파일을 여러 블록으로 저장
- 첫번째 블록을 저장하기 위해 namenode에 저장 작업 요청
- namenode는 블록 저장을 위한 datanode 3개를 선정해서 목록을 전달
- client는 전달받은 목록 중에서 첫번째 datanode에 데이터 전송
- 데이터를 전달받은 첫번째 datanode는 그다음 datanode에 데이터 전달, 그 다음 datanode는 그 다음의 datanode에 데이터를 전달한다.
- 모든 datanode가 데이터 블록을 저장하고 나면 namenode에 DONE 신호 전송
- 남은 블록에 대해서도 위의 과정을 동일하게 수행하고, 파일을 닫는다.
- namenode는 해당 파일의 metadata를 저장한다.
hdfs 상에서 파일 수신 과정
- 클라이언트 측에서는 namenode에 원하는 파일에 대한 정보를 요청한다.
- namenode로 부터 전달받은 정보를 토대로 가장 가까운 노드로부터 블록을 받기 시작하여 모든 블록을 받는닫.
- 모든 데이터 블록을 받고 나면 하나의 파일로 저장하고 수신을 완료한다.
HDFS의 오류 및 장애대응
namenode에 오류가 발생하면 모든 클러스터가 죽는 문제가 발생한다. –> 그 만큼 namenode가 핵심 역할을 수행하는 것을 확인할 수 있다.
datanode 오류 처리
namenode는 mongodb의 replica set과 유사하게 3초 단위로 heartbeat을 확인하여 datanode가 살아있는지 확인한다. 만일 10분동안 heartbeat을 못 받게되면 해당 datanode가 다운 되었음을 인지한다.
데이터 송수신 오류 처리
client는 datanode에 데이터를 전송하게 되며 그에 따른 ACK 응답을 보내는데, 만일 지속적으로 데이터를 보냈음에도 ACK 응답을 받지 못하는 경우에는 네트워크 오류로 판단한다.
데이터 checksum 확인
- 데이터 전송시 데이터에 대한 checksum을 같이 보내서 저장한다.
- datanode는 주기적으로 namenode에 block report을 보내게 되는데, 이때, checksum을 확인해서 데이터 블록이 손상되었는 지 여부를 판단한다.
- namenode는 block report을 통해 데이터를 관리한다.
Hadoop에서의 Map Reduce
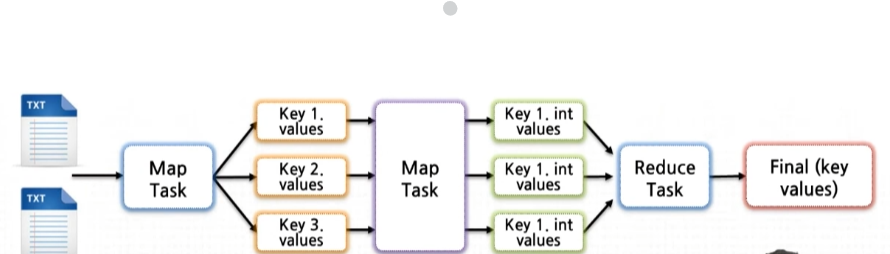
- 전달받은 input data에 대해 map 함수를 통해
<key,value>쌍으로 전환 - map():입력을 출력 키와 연관시켜 1:N 개의
<key,value>생성 - 중간 산출물에 대해 정렬하고 하나의 key 값으로 합쳐서 reduce task을 생성하는 과정을 거친다.
- reduce(): 같은 출력 키를 가지는 final value로 중간 value들을 통합
map, reduce는 모두 병렬적으로 동작하게 되며, 모든 value들은 독립적으로 처리 된다. 다만, reduce의 경우 이전의 map 연산이 모두 완료되지 않으면 시작할 수 없는 병목점을 가지고 있다. map, reduce 함수에 대해서 인터페이스로 제공하여 사용자로 하여금 사용자 편의성을 제공한다.
MongoDB에서의 Map Reduce
MongoDB에서는 기존의 RDBMS에서 AVG,SUM, 등과 같은 집계 연산에 대한 함수들을 제공하지 않는다. 대신, Map Reduce를 통해 위의 집계 기능을 구현할 수 있다.
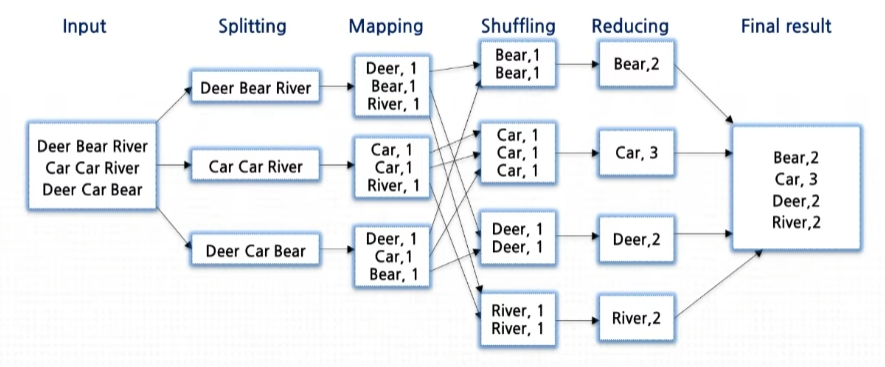
Map Reduce를 활용하여 Word Count 구하기
전체적인 동작환경 및 map, reduce 함수 설계
split mapper
input으로 전달받은 1줄의 문자열에 대해서 word 단위로 추출하는 map 함수
map(key,value):
for each word w in value:
emit(w,1)
--> ("text", "read a book") --> [("read",1),("a",1),("book",1)]
sum reducer
같은 키로 이루어진 중간 값 리스트에 대해 하나의 final value로 집계하는 reduce 함수
reduce(key,intermediate_vals):
sum=0
for each v in intermediate_vals:
sum+=v
emit(key,sum)
--> ("A",[1,2,3,4]) --> ("A",10)
전체적인 map reduce 과정
Map Reduce 구현
map 함수
map=function(){
var res=this.text.split(" ");
for(var i in res){
key={word:res[i]};
value={count:1}
emit(key,value);
}
}
모든 document에 대해서 실행되기 때문에 따로 input parameter을 지정할 필요가 없다.
reduce 함수
reduce=function(key,values){
var totalcount=0;
for(var i in values){
totalcount+=values[i].count;
}
return {count:totalcount};
}
각각의 출력 키에 대해서 중간값 리스트를 통합해서 하나의 totalcount 집계를 수행해서 각각의 출력키에 대한 totalcount 쌍을 document을 저장한다.
map reduce 실행
//테스트 데이터 삽입
db.words.insertMany([{text:"read a book"},{text:"write a book"}])
//map reduce 실행, map,reduce를 실행하고 결과를 wordcount collection에 삽입
db.words.mapReduce(map,reduce,"wordcount")
//map reduce에 대한 실행 결과 확인
//db.wordcount.find()
결과
Enterprise test> db.wordcount.find()
[
{ _id: { word: 'read' }, value: { count: 1 } },
{ _id: { word: 'write' }, value: { count: 1 } },
{ _id: { word: 'a' }, value: { count: 2 } },
{ _id: { word: 'book' }, value: { count: 2 } }
]
댓글남기기