
MongoDB 11
NoSQL + RDBMS
기존의 RDBMS 시스템의 경우, 지나치게 RDBMS에 의존하는 형태로, 우선순위가 낮고 대량의 트랜잭션을 발생시키는 데이터로 인하여 비중이 높은 데이터에 대한 처리 성능이 저하되는 문제를 야기한다. NoSQL을 도입하여, 대량의 트랜잭션을 처리함에 따라 RDBMS을 활용하여 중요한 데이터를 처리하는데 집중시키므로써 성능을 높일 수 있다.
Application Side Join
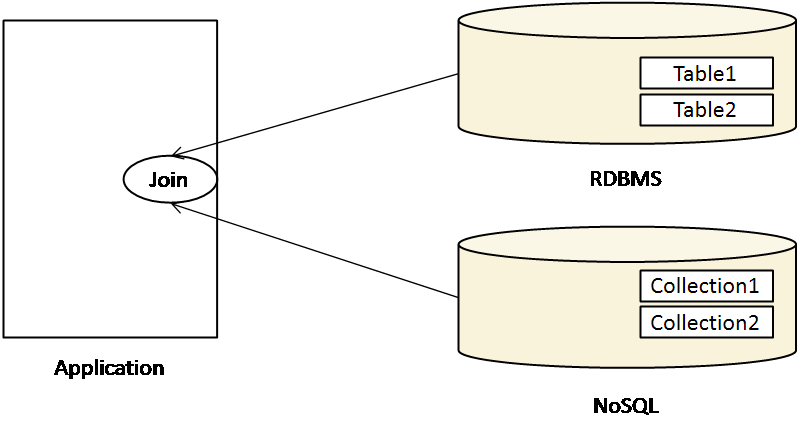
RDBMS + NoSQL을 복합적으로 이용하는 시스템을 통해 하나의 DB가 아닌, 여러 개의 DB에 저장된 데이터를 가져와서 client 측에서 join하는 Applicaion Side Join 과정이 요구된다.
Data Import/Export

복합적인 DB을 사용함에 따라 Data를 주고 받을때에도 신경을 써야한다. Hadoop의 경우 key:value 형태의 hdfs으로 이루어진 데이터 저장 방식을 가지게 되는데, RDBMS 상의 데이터를 Hadoop에서 활용하고자 하면 Sqoop과 같은 Hadoop Ecosystem을 활용하여 데이터를 변환해야한다.
정형화된 데이터에 대한 처리
- sqoop
- hiho
비정형화된 데이터 처리
- flume
- scribe
Batch Processing
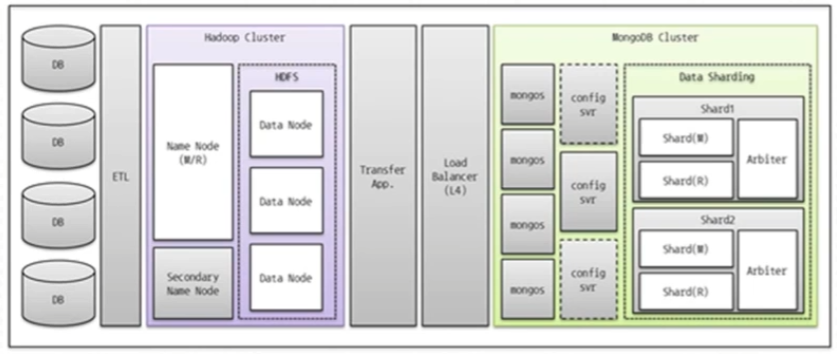
빅데이터을 활용하는 경우, 실시간으로 사용자의 쿼리를 처리하는 대화형 시스템이 아닌, 일괄적으로 다량의 데이터를 처리하는 배치형 데이터 처리를 진행한다. 병렬/분산 처리를 지원하는 MapReduce 형태를 많이 사용하며, 대표적인 것이 바로 Hadoop이다.
BigData Crawling/Processing/Service
Crawling
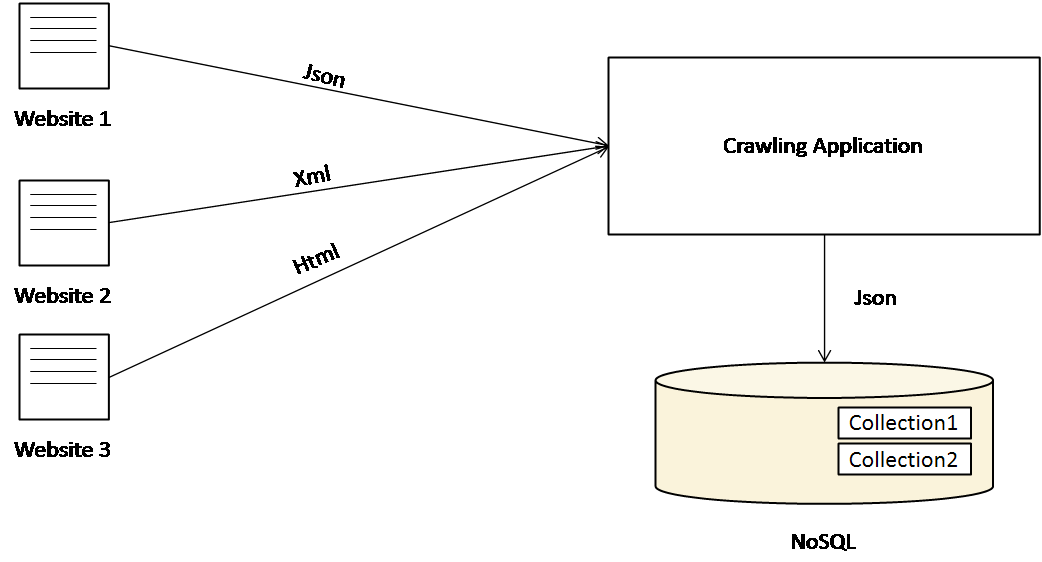
다양한 웹 기반의 서비스에서 제공하는 Rest API를 통해 JSON, XML 형태의 데이터를 수집하거나, Web Crawling을 통해 HTML 데이터를 수집한다.
다량의 데이터를 저장하는 목적이다 보니 RDBMS 보다는 NoSQL을 활용하는 것이 더 효율적이다.
Analyze
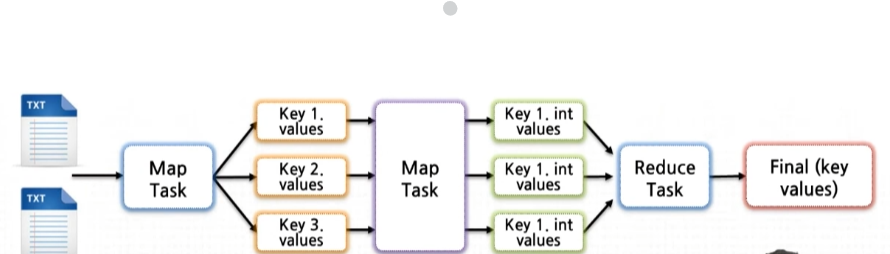
수집된 웹 상의 데이터를 Hadoop에 저장하여 분산/병렬처리를 진행하기 위해 HDFS 상에 데이터를 import(sqoop을 통한 데이터 변환 작업 수행)한다. 분석 결과에 대해서는 서비스에 사용되는 주요 데이터베이스 형태에 맞게 export하는 작업을 거친다.
수집 + 분석의 작업의 경우 물리적으로 실시간으로 처리하기는 불가능하기 때문에 실행주기를 짧게 설정하여 최대한 실시간에 가까운 데이터를 생성하도록 한다.
Service
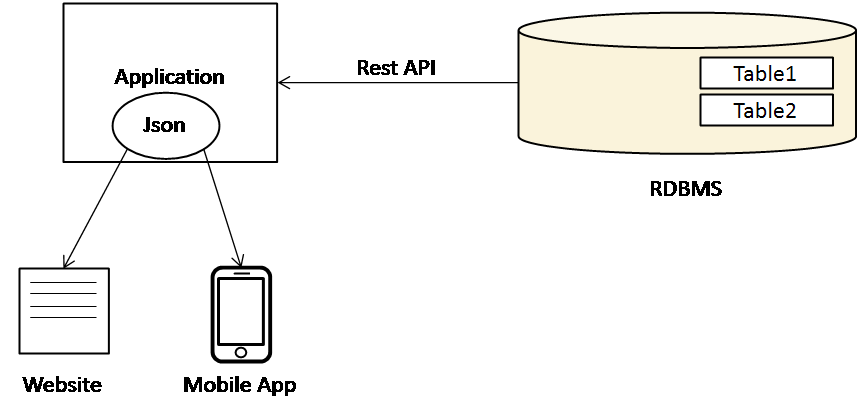
기존의 RDBMS만을 활용하는 시스템에서는 최신의 데이터를 갱신하는데 시간이 많이 걸린다는 문제점이 있었지만, MapReduce 기반의 Hadoop을 결합한 복합 시스템을 통해 빠른 병렬처리를 통한 데이터 분석으로 사용자에게 데이터를 제공하는 오버헤드가 감소하였다.
Multiplatform Chat Service

- 계정과 같은 중요한 데이터는 RDBMS인 MySQL에 저장
- 채팅 서비스를 운영하면서 발생하는 로그성 데이터는 NoSQL인 MongoDB에 저장
- Redis의 public/subscribe 기능을 활용하여 새로운 글이 등록되었을 때, push한 기능을 수행
- website의 경우 직접적인 pub/sub 기능활용을 하지 못하므로 socket.io을 활용
댓글남기기