
Kubernetes AutoScaling
Kubernetes AutoScaling
Cluster Level Scalability
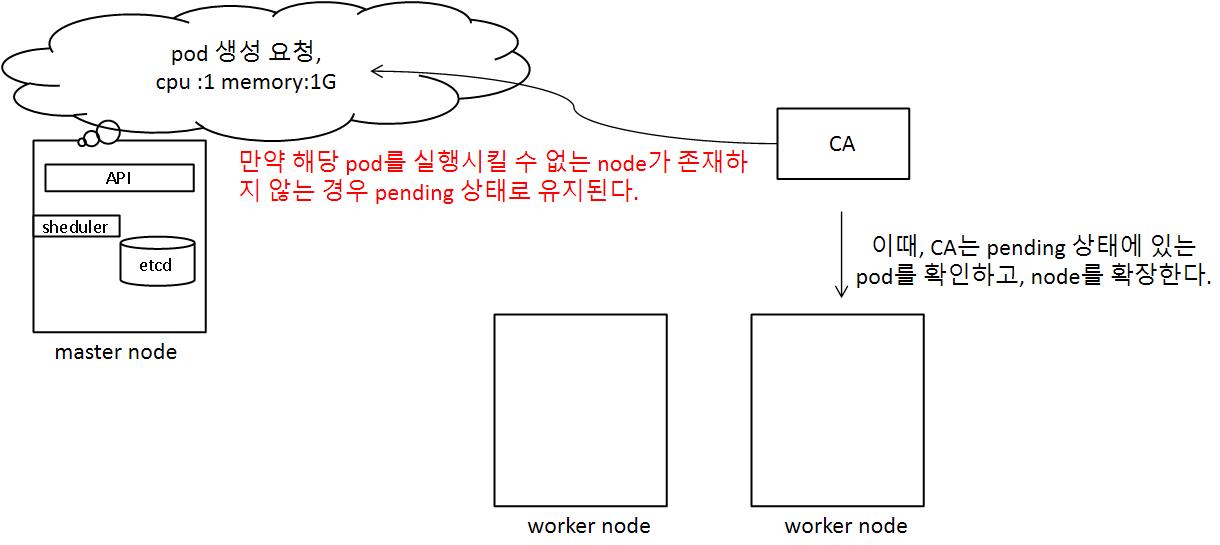
위와 같이 pod가 pending 상태에 있는 것을 확인하고 resource 부족으로 실행할 수 있는 node가 없는 경우, node를 확장시켜서 pod가 실행될 수 있도록 한다.
cluster level scalability에서는 worker node를 확장 할 수 있는 기능이 있어야하므로 주로 AWS, GCP와 같은 CSP(Cloud Server Platform) 환경에서 사용된다.
확장된 node가 실행되다가, 장시간 동안 실행되지는 않는 경우, 자동으로 해당 node를 삭제할 수 있도록 한다.
Pod Level Scalability
pod level의 경우 cluster 처럼 node를 확장 시키는 것이 아니라, pod를 확장시키는 개념이다.
| scaler | description |
|---|---|
| horizontal pod autoscaler | pod의 개수를 확장시키는 개념 |
| vertical pod autoscaler | pod의 resource를 추가 하는 개념 |
HPA Horizontal Pod AutoScaler
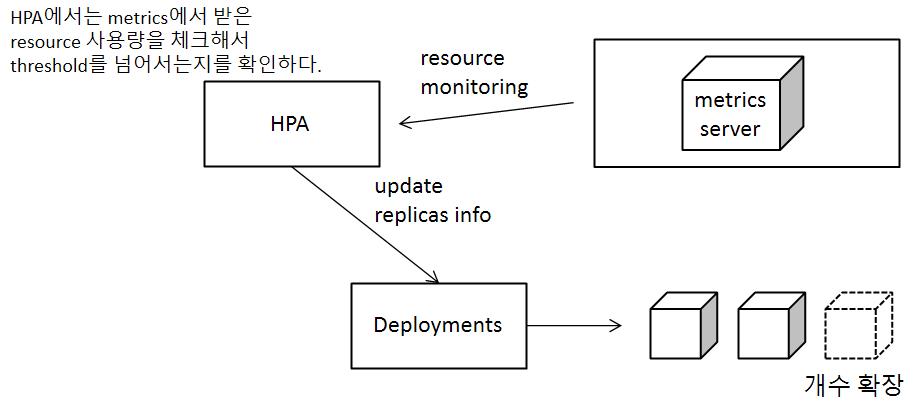
HPA를 이용해서, pod의 resource 사용량에 따라서 유동적으로 pod의 개수를 늘리고 줄일 수 있도록 지원한다.
그렇게 하려면 각각의 pod의 자원 사용량을 모니터링 할 수 있어야하는데, 이를 위해 metrics server라는 것이 동작되어야한다. metrics server는 pod 형태로 동작하게 되며 각각의 pod의 자원 사용량을 체크해서 etcd에 저장한다. 그러면 HPA에서는 자원 사용량을 이용해서 실제 필요한 pod의 개수를 계산하여 deployment을 이용해서 pod 개수를 조정한다.
VPA Vertical Pod AutoScaler
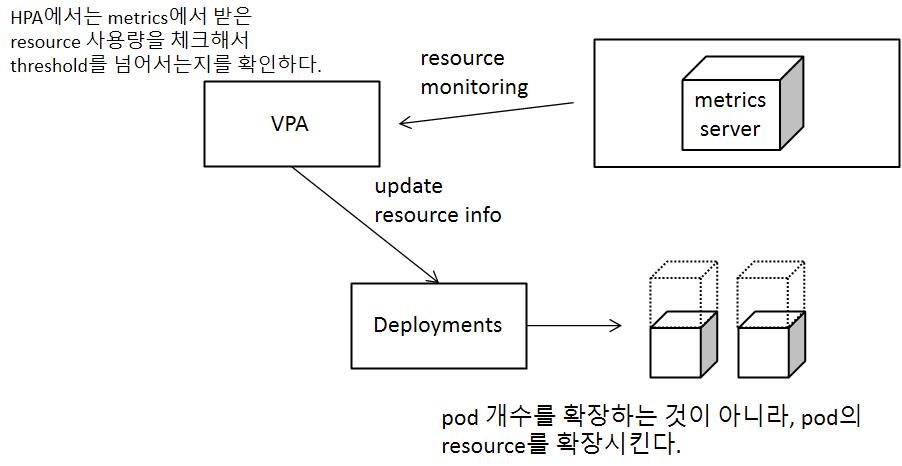
HPA와 동작과정이 유사하지만, pod의 개수를 늘려주는 것이 아니라, pod에 할당된 resource를 확장시키는 개념으로 동작한다.
Practice
실제로 AutoScaler 환경을 구성해보자
Metrics Server 설치
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
kubectl apply -f components.yaml
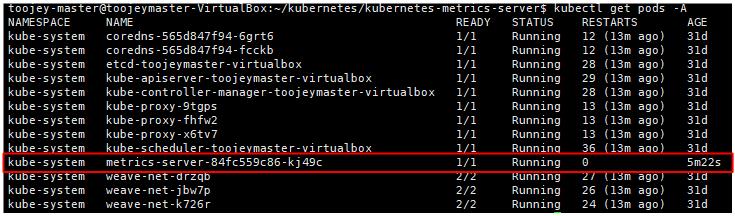
위와 같이 metrics-server와 관련된 yaml 파일을 실행하게 되면 아래와 같이 metrics-server pod가 동작하며, metrics을 활용해서 node의 resource 사용량을 파악할 수 있다.
toojey-master@toojeymaster-VirtualBox:~/kubernetes/kubernetes-metrics-server$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
toojeymaster-virtualbox 158m 5% 1265Mi 67%
toojeynode1-virtualbox 45m 1% 686Mi 36%
toojeynode2-virtualbox 26m 0% 667Mi 35%
동작환경 구성
CPU resource를 차지하는 도커 컨테이너
<?php
$x=0.0001;
for($i =0; $i<=1000000;$i++){
$x +=sqrt($x);
}
echo "OK!";
?>
FROM php:5-apache
ADD index.php /var/www/html/index.php
RUN chmod a+rx index.php
위의 연산은 매번의 호출마다 100만번의 연산을 수행하는 무거운 CPU 연산으로 request가 많아지게되면 resource를 더욱 많이 차지하게 되고, pod의 resouce 할당량을 넘어설 수 있다.
위의 컨테이너를 기반으로 deployment와 service 생성
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-web
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: smlinux/hpa-example
name: c1
ports:
- containerPort: 80
resources:
requests:
cpu: 200m
limits:
cpu: 500m
---
apiVersion: v1
kind: Service
metadata:
name: svc-web
spec:
type: ClusterIP
clusterIP: 10.96.100.100
ports:
- port: 80
targetPort: 80
selector:
app: web
deployment을 구성할때, pod의 limit을 설정해줘야 hpa에서 autoscaling이 정상적으로 동작이 가능하다.
HPA 구성
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-web
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deploy-web
targetCPUUtilizationPercentage: 50
| properties | description |
|---|---|
| max,minReplicas | 최대,최소 replicas 개수 조정 |
| scaleTargetRef | auto scale을 적용할 대상 선택 |
| targetCPUUtilizationPercentage | CPU 사용량이 %이상 넘어설 경우 replicas를 늘려준다. |
실제 동작
초기에는 아래와 같이 pod가 1개만 동작중인 상황이다.

이제, 해당 service에 대해 요청을 많이 했을 때, replicas가 어떻게 변하는 지 확인해보자
curl을 통해 service를 무한히 요청
while true;
do curl 10.96.100.100;
done
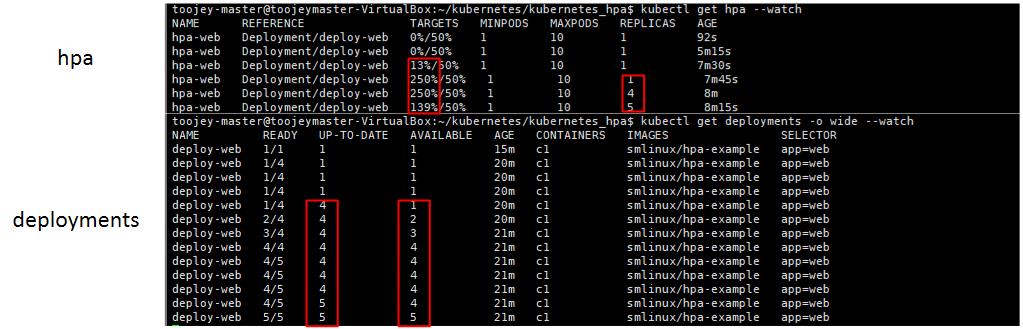
cpu resource가 늘어남에 따라 replicas 개수가 자동적으로 증가되는 것을 확인할 수 있다.
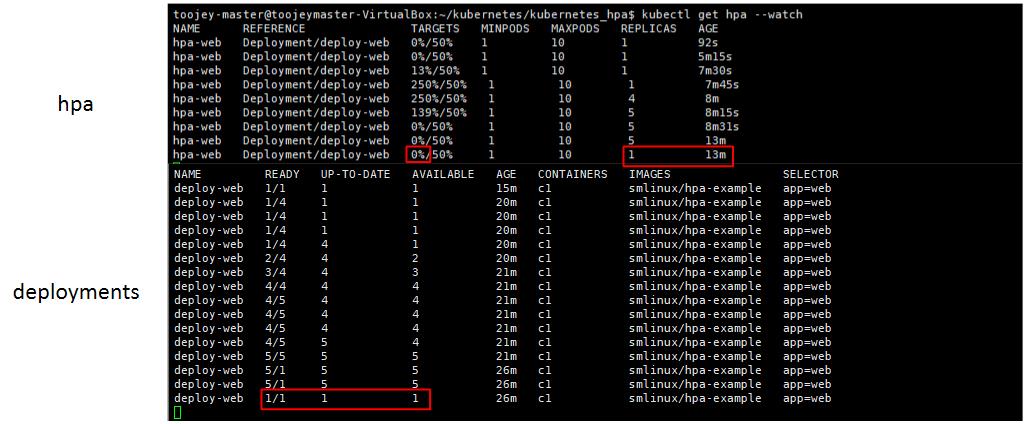
요청이 마무리되고 cpu resource가 감소하게 되면 자동적으로 pod 개수가 줄어들게 되는데, 줄어들때는 갑작스런 요청을 대비해서 5분 정도 대기한 후 replicas 개수를 줄이게 된다.
댓글남기기