
JPA part 11
Criteria, Query DSL, NativeSQL
Criteria
JPQL을 자바 코드로 작성하도록 도와주는 빌더 클래스이다. 문자열로 이루어진 jpql을 메소드 방식으로 사용할 수 있게 만들어 컴파일 단계에서 오류를 찾아 내도록 해주는 장점이 있지만, 코드가 복잡하고 직관적인 이해가 어렵다는 단점이 있다.
Basic Methods
CriteriaBuilder
//JPQL : select m from Member m
CriteriaBuilder cb = em.getCriteriaBuilder();
CriteriaQuery
//Criteria 생성, 반환 타입 지정
CriteriaQuery<Member> cq = cb.createQuery(Member.class);
FROM, SELECT 구문
Root<Member> m = cq.from(Member.class); // FROM 절
cq.select(m); // SELECT 절
TypedQuery<Member> query = em.createQuery(cq);
List<Member> resultList = query.getResultList();
Root
Print Results
System.out.println("**************");
for (Member member : resultList) {
System.out.println("member id = " + member.getId() + ", member name = " + member.getUsername());
}
Conditions, Sortings
//조건문 추가
//검색 조건 정의
Predicate usernameEquals = cb.equal(m.get("username"), "지한");
//정렬 조건 정의
javax.persistence.criteria.Order ageDesc = cb.desc(m.get("age"));
//쿼리 생성
cq.select(m)
.where(usernameEquals)
.orderBy(ageDesc);
Criteria Query
CriteriaBuilder cb=em.getCriterialBuilder();
CriteriaQuery<Member> cq=cb.CreateQuery("Member.class");
criteria 기반의 쿼리를 위해서 Criteria Query 객체를 생성해서 반환되는 타입을 지정해야한다.
만약 반환형을 지정할 수 없거나, 두 개 이상인 경우, Object 또는 Object[] 활용한다.
Tuple Type
Criteria 쿼리에서는 반환형이 여러 개인 Query에 대해서 Tuple 자료형을 제공한다.
CriteriaBuilder cb = em.getCriteriaBuilder();
// 조회값 반환 타입 : Tuple
CriteriaQuery<Tuple> cq = cb.createTupleQuery();
...
TypedQuery<Tuple> query = em.createQuery(cq);
//쿼리 생성
cq.select(
cb.tuple(m.alias("m"), m.get("username").alias("username")))
List<Tuple> resultList = em.createQuery(cq).getResultList();
System.out.println("**************");
for (Tuple tuple : resultList) {
Member member = tuple.get("m", Member.class);
String username = tuple.get("username", String.class);
System.out.println("member id = " + member.getId() + ", member name = " + member.getUsername() + ", " + username);
}
튜플을 이용해서 조회하고자 하는 대상에 대한 별칭을 지정하고, 별칭을 이용한 조회를 할 수 있다. 튜플을 사용하고자 할때는 별칭을 지정하는 것이 필수이다
Select, Multiselect, etc Keywords
Select
조회 대상이 아래와 같이 한 건 인경우 select을 이용해서 쿼리를 수행하면 된다.
//jpql: select m from Member m
cq.select(m);
Multiselect
조회 대상이 여러 개인경우 multiselect을 이용한다.
//jpql:select m.username,m.age from Member m
cq.multiselect(m.get("username"),m.get("age"));
Select + array
cq.select(cb.array(m.get("username"),m.get("age")))
DISTINCT
cq.select(cb.array(m.get("username"),m.get("age"))).distinct(true);
cq.multiselect(m.get("username"),m.get("age")).distinct(true);
select, multiselect 메소드 뒤에 distinct(true)를 체이닝해서 distinct 키워드를 사용할 수 있다.
new
Criteria에서는 new 대신 construct을 이용한다.
class UserDTO{
private String username;
private int age;
public UserDTO(String username, int age){
this.username=username;
this.age=age;
}
}
cq.select(cb.construct(UserDTO.class,m.get("username"),m.get("age")));
cb.construct를 이용해서, 생성할 쿼리 클래스타입을 지정하고, 필드값들을 넘겨준다. jpql과 달리 객체형태로 전달하게 되므로 패키지 명까지 명시하지 않아도 된다.
Group By
Expression maxAge=cb.max(m.<Integer>get("age"));
Expression minAge=cb.min(m.<Integer>get("age"));
cq.multiselect(m.get("team").get("name"), maxAge, minAge);
cq.groupBy(m.get("team").get("name"));
Expression을 이용해서 집합함수를 사용할 수 있고, cq.groupBy 메소드를 이용해서 group을 위한 컬럼을 지정한다.
Having
cq.multiselect(m.get("team").get("name"), maxAge, minAge);
cq.groupBy(m.get("team").get("name"));
cq.having(cb.gt(minAge,10))
각 팀에서 최연소 나이가 10 초과인 팀을 선택한다.
Order
cq.orderBy(cb.desc(m.get("age")));
cq.OrderBy를 이용해서 정렬을 수행한다.
Join
JoinType
public enum JoinType{
INNER,
LEFT,
RIGHT
}
Join query
Root<Member> m = cq.from(Member.class);
Join<Member, Team> t = m.join("team", JoinType.INNER); // 내부조인
cq.multiselect(m, t)
.where(cb.equal(t.get("name"), "팀A"));
Join<> 클래스로 연관된 엔티티들을 명시하고, join 메소드에는 연관필드와 조인 타입을 명시한다.
Join<Member, Team> t = m.join("team", JoinType.LEFT);
Join<Member, Team> t = m.join("team", JoinType.RIGHT);
LEFT OUTER, RIGHT OUTER은 위와 같이 진행하면 된다.
Fetch Join
Root<Member>m =cq.from(Member);
m.fetch("team",JoinType.LEFT);
fetch 메소드를 이용해서 fetch join을 수행할 수 있다.
서브쿼리
Simple Subquery
서브쿼리가 메인쿼리의 컬럼을 사용하지 않을때는 아래와 같이 사용하면 된다.
//jpql select m from Member m where m.age >= (select AVG(m2.age) from Member m2)
CriteriaQuery<Member> mainQuery = cb.createQuery(Member.class);
//Subquery
Subquery<Double> ageSubQuery = mainQuery.subquery(Double.class);
Root<Member> m2 = ageSubQuery.from(Member.class);
ageSubQuery.select(cb.avg(m2.get("age")));
//Main query
Root<Member> m = mainQuery.from(Member.class);
mainQuery.select(m);
mainQuery.where(cb.ge(m.<Integer>get("age"), ageSubQuery));
Subquery 객체를 이용해서 서브 쿼리를 생성한다음, where조건절에 Subquery 객체를 인자로 전달해서 적용한다.
Correlated Subquery
만약 서브쿼리에서 메인쿼리에 있는 컬럼을 사용하고자 하면 아래와 같이 한다.
//jpql: select m from Member m where exists(select t from m.team where t.name="팀A")
CriteriaQuery<Member> mainQuery = cb.createQuery(Member.class);
Root<Member> m = mainQuery.from(Member.class);
//Sub Query
Subquery<Long> subQuery = mainQuery.subquery(Long.class);
Root<Member> subM = subQuery.correlate(m);
Join<Member, Team> t = subM.join("Team");
subQuery.select(cb.equal(t.get("name"),"팀A"));
//Main Query
mainQuery.select(m)
.where(cb.exits(subQuery));
subquery.correlate를 이용해서 메인 쿼리로부터 별칭을 얻어와서 이를 서브 쿼리에서 활용한다.
연산식
In
//jpql: select m from Member m where m.username in("회원1", "회원2")
//cb,cq,m
cq.select(m).where(cb.in(m.get("username")).value("회원1").value("회원2"))
cb.in 과 value 메소드를 이용해서 in 연산 수행 가능
Case
/*jpql:
select m.username
case when m.age>=60 then 600,
when m.age<=15 then 500,
else 1000
end
from Member m
*/
//cb,cq,m
cq.multiselect(
m.get("username"),
cb.selectCase()
.when(cb.ge(m.<Integer>get("age",60),600))
.when(cb.le(m.<Integer>get("age",15),500))
.otherwise(1000));
selectCase, when, otherwise를 이용해서 case 연산식을 표현할 수 있다.
Parameter
criteria 에서도 parameter을 지정해서 쿼리를 수행할 수 있다.
//jpql: select m from Member m where m.username= :userNameParam
cq.select(m)
.where(cb.equal(m.get("name"),
cb.parameter(String.class, "userNameParam")));
List<Member> members = em.createQuery(cq)
.setParameter("userNameParam", "회원1")
.getResultList();
쿼리문을 생성할때, parameter 메소드를 이용해서 query parameter을 지정하고 나중에 setParameter을 이용해서 변수값을 등록한다.
이러한 parameter 메소드를 이용하게 되면 실행 환경에 따라 바뀌는 동적 쿼리를 만들 수 있다.
Appendix
그외에도 jpql에서 사용한 다양한 함수에 대해서 메소드로 제공한다.
Meta Model API
Criteria를 이용하게 되면 문자열 기반의 jpql을 객체와 메소드 형태로 구현할 수 있게되어 컴파일 수준에서 오류를 찾아낼 수 있다. 하지만 여전히 에러가 발생할만한 요소가 있다.
cq.select(m)
.where(cb.gt(m.<Integer>get("age"), 20))
.orderBy(cb.desc(m.get("age")));
위와 같이 엔티티의 컬럼값을 찾으려면 컬럼명으로 접근하게 되는데, 이때 컬럼명을 문자열로 전달하기 때문에 철자에 오류가 발생해도 컴파일 단계에서는 찾아낼 수 없다. 이러한 부분을 해결하기 Meta Model API를 활용한다.
cq.select(m)
.where(cb.gt(Member_.age), 20)
.orderBy(cb.desc(m.get(Member_.age)));
위와 같이 Meta Model API 기반으로 코드를 작성하기 위해서는 Member_라는 메타 클래스가 필요하다.
다행히도, 이러한 메타 클래서는 Criteria 에서 자동을 생성해준다.
하이버네이트 구현체에서는 아래의 코드 생성기를 이용해서 엔티티에 대한 메타 클래스를 만든다.
org.hibernate.jpamodelgen.JPAMetaModelEntityProcessor
코드 생성기 정보만 project에 등록해주면 메타 클래스는 코드생성기를 이용해서 자동으로 생성된다.
pom.xml
<!-- 메타모델 생성기 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-jpamodelgen</artifactId>
<version>1.3.0.Final</version>
</dependency>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<compilerArguments>
<processor>org.hibernate.jpamodelgen.JPAMetaModelEntityProcessor</processor>
</compilerArguments>
</configuration>
</plugin>
</plugins>
</build>
pom.xml에 위의 설정을 등록한다.
그런 다음 아래의 명령어를 수행하고 나면 /target/generated-sources/annotations 하위 폴더에 메타클래스들이 생성된다.
maven compile
QueryDSL
criteria를 이용하면 객체, 메소드 기반으로 jpql을 생성할 수 있어 컴파일 단계에서 오류를 찾아낼 수 있다는 장점이 있다. 하지만, 복잡하고 직관성이 떨어진다는 단점이 있는데, jpql를 보다 효과적으로 빌드해줄 수 있는 빌더 API 가 있는데, QueryDSL이다.
Configurations
pom.xml
<!-- QueryDSL -->
<dependency>
<groupId>com.mysema.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
<version>3.6.3</version>
</dependency>
<!-- QueryType 생성 라이브러리 -->
<dependency>
<groupId>com.mysema.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
<version>3.6.3</version>
</dependency>
| Library | Description |
| querydsl-jpa | QueryDSL JPA 라이브러리 |
| querydsl-apt | 쿼리 타입(Q)를 생성할 때 필요한 라이브러리 |
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt-maven-plugin</artifactId>
<version>1.1.3</version>
<executions>
<execution>
<goals>
<goal>process</goal>
</goals>
<configuration>
<outputDirectory>target/generated-sources/java</outputDirectory>
<processor>com.mysema.query.apt.jpa.JPAAnnotationProcessor</processor>
</configuration>
</execution>
</executions>
</plugin>
위의 설정을 추가하게 되면 Criteria와 유사하게 작동하는 쿼리 타입 클래스들을 생성하는 라이브러리를 등록할 수 있다.
maven compile
명령어를 수행하고 나면 /target/generated-sources/annotations 하위 폴더에 쿼리 타입 클래스들이 생성된다.
JDK 11
java version 11이 되면서 특정 모듈에 대해서 deprecated 되면서 삭제 되었는데, 그렇게 되면서 javax class에 대한 ClassNotFoundError가 발생한다. 따라서 아래와 같이 2개의 library에 대한 dependency를 추가해줘야한다.
<!-- javax annotation -->
<dependency>
<groupId>javax.annotation</groupId>
<artifactId>javax.annotation-api</artifactId>
<version>1.3.2</version>
</dependency>
<!-- jaxb -->
<dependency>
<groupId>jakarta.xml.bind</groupId>
<artifactId>jakarta.xml.bind-api</artifactId>
<version>2.3.2</version>
</dependency>
QueryDSL Queries
JPAQuery
JPAQuery query = new JPAQuery(em);
QueryDSL을 활용하기 위해 JPAQuery 객체를 생성한다.
Qmember
QMember qMember = new QMember("m");// 생성되는 JPQL의 별칭이 m
쿼리타입을 지정해준다. –> 쿼리 타입 클래스를 설정해주는 작업이다.
Query
List<Member> members = query
.from(qMember)
.where(qMember.username.eq("철수"))
.orderBy(qMember.username.desc())
.list(qMember);
for (Member member : members) {
System.out.println("Member : " + member.getMemberId() + ", " + member.getUsername());
}
그 외의 부분은 Criteria와 크게 다르지 않다.
아래의 예시를 통해 쿼리들을 알아보자
Where
JPAQuery query = new JPAQuery(em);
QItem item = QItem.item;
List<Item> list = query.from(item)
.where(item.name.eq("좋은상품").and(item.price.gt(20000)))
.list(item);
각각의 컬럼에 대해 직접 eq,gt와 같은 연산자를 호출할 수 있고, and, or 와 같은 연산자도 제공한다.
item.price.between(1000, 2000); // 가격이 10000원~20000원 상품
item.name.contains("상품1"); // 상품1 이름을 포함하는 상품
item.name.startsWith("고급"); // like 검색
Query Results
결과를 조회하는 메소드는 아래와 같이 세 종류가 존재한다.
| Method | Description |
|---|---|
| uniqueResult() | 조회 결과가 한 건 일때 사용, 없으면 null, 하나 이상은 예외 |
| singleResult() | uniqueResult()와 같지만 하나 이상이면 첫번째 반환 |
| list() | 결과가 하나 이상일 경우, 없으면 빈 컬렉션 |
Join
QOrder order = QOrder.order;
QMember member = QMember.member;
QOrderItem orderItem = QOrderItem.orderItem;
//Join method .[inner]join,.leftJoin,rightJoin,fullJoin
query.from(order)
.join(order.member, member)
.leftJoin(order.orderItems, orderItem)
.list(order)
//join on
query.from(order)
.leftJoin(order.orderItems, orderItem)
.on(orderItem.count.gt(2))
.list(order);
//fetch join
query.from(order)
.innerJoin(order.member, member).fetch()
.leftJoin(order.orderItem, orderItem).fetch()
.list(order)
//theta join
query.from(order, member)
.where(order.member.eq(member))
.list(order)
조인을 수행하는 방법도 criteria와 매우 흡사하다.
Subquery
서브 쿼리를 이용할때는 JPASubQuery를 생성해서 WHERE 절에 추가해준다.
단항 서브 쿼리
QItem item = QItem.item;
QItem itemSub = new QItem("itemSub")
query.from(item)
.where(item.price.eq(
new JPASubQuery().from(itemSub).unique(itemSub.price.max())
))
.list(item);
unique를 이용해서 쿼리 결과를 하나만 반환한다.
다항 서브 쿼리
QItem item = QItem.item;
QItem itemSub = new QItem("itemSub");
query.from(item)
.where(item.in(
new JPASubQuery().from(itemSub)
.where(item.name.eq(itemSub.name))
.list(itemSub)
))
.list(item);
list를 이용해서 쿼리 결과를 여러개를 반환한다.
Projection
select에서 조회할 컬럼들을 지정해준다.
하나의 컬럼에 대한 조회
QItem item = QItem.item;
List<String> result = query.from(item).list(item.name);
for (String name : result) {
System.out.println("name = " + name);
}
여러 컬럼 반환
QItem item = QItem.item
List<Tuple> result = query.from(item).list(item.name, item.price);
//List<Tuple> result = query.from(item).list(new QTuple(item.name, item.price)); // 동일
for (Tuple tuple : result) {
System.out.println("name = " + tuple.get(item.name));
System.out.println("price = " + tuple.get(item.price));
}
쿼리 타입 클래스를 이용해서 튜플에서 컬럼 값을 가져올 수 있다.
객체 형태의 반환
jpql의 new에 대응되는 개념으로 객체 형태로 반환받을 수 있다.
ITEM DTO
class ItemDTO{
private String username;
private int price;
public ItemDTO();
public ItemDTO(String username, int price){
this.username=username;
this.price=price;
}
//Getter, Setter
}
Getter/Setter 활용
QItem item=QItem.item;
List<ItemDTO> resultList=query.from(item).list(
Projection.beans(ItemDTO.class,item.name.as("username"),item.price)
);
Projection.beans을 이용하면 getter/setter을 이용해서 클래스를 만들게 된다.
ItemDTO에 명시된 컬럼과 쿼리 결과의 컬럼명이 다르면 as 별칭을 이용해서 지정해준다.
Field 활용
QItem item=QItem.item;
List<ItemDTO> resultList=query.from(item).list(
Projection.fields(ItemDTO.class,item.name.as("username"),item.price)
);
Projection.fields을 이용하면 필드에 직접 접근해서 클래스를 생성한다.
Constructor 활용
QItem item=QItem.item;
List<ItemDTO> resultList=query.from(item).list(
Projection.constructor(ItemDTO.class,item.name,item.price)
);
Projection.constructor을 이용하면, 생성자를 이용한 클래스 생성이 가능하다.
동적 쿼리 생성
SearchParam param = new SearchParam();
param.setName("시골개발자");
param.setPrice(10000);
QItem item = QItem.item;
BooleanBuilder builder = new BooleanBuilder();
if (StringUtils.hasText(param.getName())) {
builder.and(item.name.contains(param.getName()));
}
if (param.getPrice() != null) {
builder.and(item.price.gt(param.getPrice()));
}
List<Item> result = query.from(item)
.where(builder)
.list(item);
위 처럼 Boolean Builder을 이용해서 상품 이름과 가격 유무에 따른 동적 쿼리를 생성해서 적용할 수 있다.
메소드 위임
쿼리타입 클래스에 검색조건을 직접 정의할 수 있다.
public class ItemExpression {
@QueryDelegate(Item.class)
public static BooleanExpression isExpensive(QItem item,int price) {
return item.price.gt(price);
}
}
특정 값보다 비싸면 true를 반환하는 메소드를 쿼리 타입 클래스에 추가하였다.
@QueryDelegate로 해당 메소드를 적용할 엔티티를 지정한다.
위와 같이 메소드를 생성하면 아래의 쿼리 타입 클래스에 직접 생성한 검색 메소드가 추가되는 것을 확인할 수 있다.
@Generated("com.querydsl.codegen.EntitySerializer")
public class QItem extends EntityPathBase<Item> {
.................
public BooleanExpression isExpensive(Integer price) {
return ItemExpression.isExpensive(this,price);
}
}
Native SQL
JPQL을 사용해서 대부분의 SQL을 실행할 수 있으나, 특정 DB에 종속적인 기능들을 수행하기 위해서는 SQL문을 활용해야한다.
In-Line View, UNION, INTERSECT, Stored Procedure 와 같은 부분은 JPQL로 처리할 수 없어 SQL문을 사용해야 한다.
이를 위해, JPQL는 Native SQL을 지원하는데, 이는 JDBC API와 달리 엔티티,영속성 컨텍스트를 이용한 sql문을 작성할 수 있다.
Native SQL Queries
// 결과 타입 정의
public Query createNativeQuery(String sqlString, Class resultClass);
// 결과 타입 정의할 수 없음
public Query createNativeQuery(String sqlString);
// 결과 매핑 사용
public Query createNativeQuery(String sqlString, String resultSetMapping);
엔티티 조회
//SQL
String sql="SELECT ID,AGE,NAME,TEAM_ID FROM MEMBER WHERE AGE >?"
List<Member> members = em.createNativeQuery(sql, Member.class)
.setParameter(1, 20)
.getResultList();
위와 같이 SQL만 SQL 기반으로 작성하며 나머지 부분은 JPQL 방식과 동일하다.
컬럼 조회
//SQL
String sql="SELECT ID,AGE,NAME,TEAM_ID FROM MEMBER WHERE AGE >?"
List<Object[]> resultList = em.createNativeQuery(sql)
.setParameter(1, 20)
.getResultList();
for(Object[] row: resultList){
System.out.println("id= " + row[0]);
System.out.println("age= " + row[1]);
System.out.println("name= " + row[2]);
System.out.println("team_id= " + row[3]);
}
위와 같이 jpql과 비슷하게 컬럼값에 대해 반환형을 정해주지 않으면 Object[]로 받을 수 있다.
결과 매핑
결과 매핑 1
//SQL
String sql="SELECT M.ID, AGE, NAME, TEAM_ID, I.ORDER_COUNT"
+ "FROM MEMBER M"
+ "LEFT JOIN"
+ "(SELECT IM.ID, COUNT(*) AS ORDER_COUNT"
+ "FROM ORDERS O, MEMBER IM"
+ "WHERE O.MEMBER_ID = IM.ID) I"
+ "ON M.ID=I.ID";
//회원 에티티와 회원이 주문한 상품수를 조회하기 위한 SQL문이다.
Query nativeQuery= em.createNativeQuery(sql,"memberWithOrderCount");
List<Object[]> resultList=nativeQuery.getResultList();
for(Object[] row: resultList){
Member member=(Member) row[0];
BigInteger orderCount=(BigInteger)row[1];
System.out.println("member= " +member);
System.out.println("orderCount= " +member);
}
아래와 같이 결과 매핑을 사용해서 쿼리 결과 지정한 결과 매핑 형태로 받을 수 있다.
memberWithOrderCount
@Entity
@SqlResultSetMapping(name="memberWithOrderCount",
entities=(@EntityResult(entityClass=Member.class)),
columns=(@ColumnResult(name="ORDER_COUNT"))
)
public class Member{
...
}
결과 매핑 2
Query nativeQuery=em.createNativeQuery(
"SELECT O.ID AS ORDER_ID, O.QUANTITY AS ORDER_QUANTITY, O.ITEM AS ORDER_ITEM, I.NAME AS ITEM_NAME"+
"FROM ORDER O, ITEM I"+
"WHERE(ORDER_QUANTITY > 25) AND (ORDER_TIME = I.ID)",
"orderResults"
)
@Entity
@SqlResultSetMapping(name="orderResults",
entities=(
@EntityResult(entityClass=com.acme.Order.class),fields=(
@FieldResult(name="id", column="order_id"),
@FieldResult(name="quantity", column="order_quantity"),
@FieldResult(name="item", column="order_time")
)),
columns=(
@ColumnResult(name="item_name"))
)
public class Order{
...
}
위와 같이 각 엔티티에 대한 field을 @FieldResult으로 매핑해줄 수 있다.
결과 매핑 관련 annotations
@SqlResultSetMapping
| Options | Description |
|---|---|
| name | 결과 매핑 이름 |
| entities | @EntityResult을 사용해서 엔티티를 결과로 매핑함 |
| columns | @ColumnResult을 사용해서 컬럼을 결과로 매핑함 |
@EntityResult
| Options | Description |
|---|---|
| entityClass | 결과로 사용할 엔티티 지정 |
| fields | 엔티티에 해당되는 필드들 @FieldResult으로 지정 |
| discriminatorColumn | 엔티티의 인스턴스 타입을 지정(상속관련) |
@FieldResult
| Options | Description |
|---|---|
| name | 결과를 받을 필드명 |
| columns | 결과 컬럼명 |
@ColumnResult
| Options | Description |
|---|---|
| name | 결과 컬럼명 |
Named Native SQL
@Entity
@NamedNativeQuery(
name="Member.memberSQL",
query="SELECT ID,AGE,NAME,TEAM_ID"+
"FROM MEMBER WHERE AGE >?",
resultClass=Member.class
)
public class Member{...}
named query를 사용하는 예제
TypedQuery<Member> nativeQuery=em.createNamedQuery("Member.memberSQL",Member.class).setParameter(1,20);
결과매핑을 named query 와 같이 사용할 수 있다.
@Entity
@SqlResultSetMapping(name="memberWithOrderCount",
entities=(@EntityResult(entityClass=Member.class)),
columns=(@ColumnResult(name="ODRER_COUNT"))
)
@NamedNativeQuery(
name="Member.memberWithOrderCount",
query="SELECT M.ID, AGE, NAME, TEAM_ID, I.ORDER_COUNT"
+ "FROM MEMBER M"
+ "LEFT JOIN"
+ "(SELECT IM.ID, COUNT(*) AS ORDER_COUNT"
+ "FROM ORDERS O, MEMBER IM"
+ "WHERE O.MEMBER_ID = IM.ID) I"
+ "ON M.ID=I.ID",
resultSetMapping="memberWithOrderCount"
)
public class Member{ ... }
예제
List<Object[]> resultList=em.createNamedQuery("Member.memberWithOrderCount");
for(Object[] row: resultList){
Member member=(Member) row[0];
BigInteger orderCount=(BigInteger)row[1];
System.out.println("member= " +member);
System.out.println("orderCount= " +member);
}
NamedNativeQuery annotations
| Option | Description |
|---|---|
| name | named query의 이름 지정 |
| query | sql 쿼리 지정 |
| hints | sql 힌트 지정 |
| resultClass | 결과 클래스 지정 |
| resultSetMapping | 결과 매핑 지정 |
XML로도 namedQuery를 지정할 수 있다.
<?xml version="1.0" encoding="UTF-8"?>
<entity-mappings
<named-native-query name="Member.memberWithOrderCount" result-set-mapping="memberWithOrderCount">
<query>
<![CDATA[
SELECT M.ID, AGE, NAME, TEAM_ID, I.ORDER_COUNT
FROM MEMBER M
LEFT JOIN
(SELECT IM.ID, COUNT(*) AS ORDER_COUNT
FROM ORDERS O, MEMBER IM
WHERE O.MEMBER_ID = IM.ID) I
ON M.ID=I.ID
]]></query>
</named-native-query>
<sql-result-set-mapping name="memberWithOrderCount">
<entity-result entity-class="jpabook.domain.Member"/>
<column-result name="ORDER_COUNT"/>
</sql-result-set-mapping>
</entity-mappings>
위와 같이 <named-native-query> 를 명시하고, <sql-result-set-mapping>을 정의해주면 named query를 사용할 수 있다.
객체 지향형 쿼리 심화
벌크 연산
엔티티를 수정하면 기존에는 영속성 컨텍스트에서 변경을 감지해서 수행했는데, 이렇게 진행하게 되면 하나의 엔티티에 대해서 수 백개 이상의 데이터를 처리하는데 시간이 많이 소요된다. 이를 위해 JPQL 기반의 Update/Delete 와 같은 벌크 연산을 수행한다.
만약, 제품의 재고가 10개 미만인 제품에 대해서 가격을 10% 상승하고자 한다면 아래와 같이 하면 된다.
String sql="update Product p"
+"set p.price=p.price*1.1"
+"where p.stockAmount < :stockAmount";
int resultCount=em.createQuery(sql)
.setParameter("stockAmount",10)
.executeUpdate();
위와 같이 executeUpdate 메소드를 이용해서 벌크연산을 수행할 수 있도록 한다.
//1000원 짜리 물건이라 가정
Product productA=
em.createQuery("select p from Product p where p.name :=name",Product.class).setParameter("name","productA").getSingleResult();
// DB에서 영속성 컨텍스트로 값을 저장하고, 해당 결과를 반환한다. --> 1000
System.out.println("product A: " + productA.getPrice());
//모든 제품에 대해 가격 10% 상승
em.createQuery("update Product p"
+"set p.price=p.price*1.1")
// DB에서 영속성 컨텍스트로 값을 저장하고, 해당 결과를 반환한다. -->1000
System.out.println("product A: " + productA.getPrice());
벌크 연산 같은 경우 바로 영속성 컨텍스트를 거치지 않고 바로 DB로 전달되게 된다. 따라서, 영속성 컨텍스트 내에 있는 정보가 수정되지 않는 문제가 발생해, 위와 같이 조회를 했을 때 수정한 결과를 출력하지 않게 된다. 이를 방지하기 위해 아래의 방법들이 있다.
- em.refresh() 벌크 연산을 수행한 후 DB에서 다시 값을 가져온다.
- 벌크 연산을 먼저 수행후 조회를 하게 되면 DB에서 수정된 값을 가져올 수 있다.
- 벌큰 연산을 수행한 후 영속성 컨텍스트를 초기화해준다. 그러면 나중에 조회시 DB에서 영속성 컨텍스트로 다시 가져오게 된다.
보통 2번의 경우를 자주 활용한다.
QueryDSL 수정,삭제 연산
수정
//jpql: update Item i set i.price=i.price*1.1 where i.name='시골개발자의 JPA 책'
QItem item=QItem.item;
JPAUpdateClause updateClause=new JPAUpdateClause(em,item);
Long count=updateClause.where(item.name.eq("시골개발자의 JPA책"))
.set(item.price,item.price.add(100))
.execute();
QueryDSL에서는 JPAUpdateClause를 이용해서 수정 연산을 수행할 수 있다.
삭제
//jpql: delete from Item i where i.name='시골개발자의 JPA 책'
QItem item=QItem.item;
JPADeleteClause deleteClause=new JPADeleteClause(em,item);
Long count=deleteClause.where(item.name.eq("시골개발자의 JPA책"))
.execute();
QueryDSL에서는 JPADeleteClause 이용해서 삭제 연산을 수행할 수 있다.
JPQL & 영속성 컨텍스트
jpql 쿼리를 수행하고 나면, 엔티티의 경우 영속성 컨텍스트에 저장되지만, 임베디드 타입이나 단순 타입 같은 경우는 영속성 컨텍스트에서 관리되지 않는다.
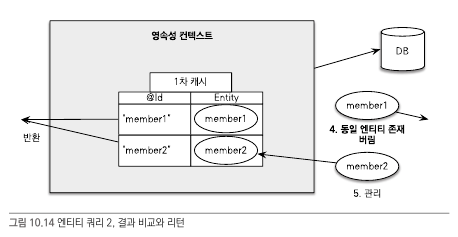
만약 아래의 em.find()로 member1 객체에 대해 이미 저장되어 있는 상태에서
em.find(Member.class, "member1");
아래와 같이 모든 Member 객체를 조회하는 jpql를 실행하면 어떻게 될까?
em.createQuery("select m from Member m",Member.class).getResultList();
위의 그림처럼, jpql로 실행된 결과 중에 이미 영속성 컨텍스트에 저장되어 있는 객체에 대해서는 버리고, 없는 객체는 영속성 컨텍스트에 추가하고 해당 객체들을 반환한다.
jpql vs em.find()
em.find()는 영속성 컨텍스트를 활용하여 엔티티를 조회하고, 만약 영속성 컨텍스트에 조회하고자하는 엔티티가 있는 경우에는 DB에 요청을 하지 않는다.
반면, jpql은 매번 DB로 호출이 이루어진다. DB에서 엔티티를 가져왔는데, 만약 영속성 컨텍스트에 엔티티가 저장되어 있으면 쿼리 결과는 삭제하고 영속성 컨텍스트에서 엔티티를 가져오게 된다.
JPQL & flush mode
플러시를 통해 영속성 컨텍스트의 변경내용이 DB에 적용된다. 지연 쓰기 SQL저장소에서 SQL들이 실행된다.
플러시 모드에는 아래와 같이 2가지 모드가 있다.
FlushModeType.AUTO –> 커밋, 쿼리 실행전에 플러시
FlushModeType.COMMIT –> 커밋시에만 플러시
JPQL에서는 플러시 모드와 상관없이 항상 DB에 쿼리를 요청한다. 따라서, 영속성 컨텍스트에 있는 변경사항이 적용되지 않은 엔티티들이 조회된다.
FlushModeType.AUTO
product.setPrice(2000);
Product product2=em.createQuery("select p from Product p where p.price=2000",Product.class).getSingleResult();
위와 같이 플러시 모드가 자동인 경우에는 아래와 같이 동작한다.
우선, 영속성 컨텍스트에 물건의 가격이 2000원으로 수정된다. DB에 바로 변경사항이 적용되고 있지 않다가 jpql의 쿼리 수행 직전에 영속성 컨텍스트의 변경사항이 적용되어 쿼리 결과 가격이 2000원이 물건이 조회된다.
FlushModeType.COMMIT
em.setFlushMode(FlushModeType.COMMIT);
product.setPrice(2000);
em.flush();
Product product2=em.createQuery("select p from Product p where p.price=2000",Product.class).setFlushMode(FlushModeType.AUTO)getSingleResult();
플러시 모드가 커밋인 경우에는, em.flush를 이용해서 직접 플러시를 수행하거나, jpql에서 setFlushMode를 통해서 쿼리 전에 영속성 컨텍스트의 변경사항이 DB에 적용될 수 있도록 해야한다.
위의 상황을 보면 플러시를 AUTO 모드로 설정하는 것이 무결성 유지를 할 수 있고, 쿼리 실행 직전 flush를 호출하지 않아도 되서 좋아보이지만, AUTO 모드로 사용하게 되면 플러시가 너무 빈번하게 발생한다는 문제가 있다.
상황에 따라서 AUTO와 COMMIT 모드 설정을 고민해야한다.
References
book: 자바 ORM 표준 JPA 프로그래밍 -김영한 저
댓글남기기